Hazelcast – 快速指南
Hazelcast – 快速指南
Hazelcast – 介绍
分布式内存数据网格
数据网格是分布式缓存的超集。分布式缓存通常仅用于存储和检索分布在缓存服务器上的键值对。但是,数据网格除了支持键值对的存储之外,还支持其他特性,例如,
-
它支持其他数据结构,如锁、信号量、集合、列表和队列。
-
它提供了一种通过丰富的查询语言(例如 SQL)来查询存储数据的方法。
-
它提供了一个分布式执行引擎,有助于并行操作数据。
Hazelcast 的好处
-
支持多种数据结构– Hazelcast 支持使用多种数据结构以及 Map。一些示例是锁、信号量、队列、列表等。
-
Fast R/W access – 鉴于所有数据都在内存中,Hazelcast 提供非常高速的数据读/写访问。
-
高可用性– Hazelcast 支持跨机器分发数据以及额外的备份支持。这意味着数据不是存储在一台机器上。因此,即使在分布式环境中频繁发生的机器宕机,数据也不会丢失。
-
高性能– Hazelcast 提供了可用于在多个工作机器之间分配工作负载/计算/查询的构造。这意味着计算/查询使用来自多台机器的资源,这大大减少了执行时间。
-
易于使用– Hazelcast 实现并扩展了许多 java.util.concurrent 结构,这使得它非常易于使用和与代码集成。在机器上开始使用 Hazelcast 的配置只需要将 Hazelcast jar 添加到我们的类路径中。
Hazelcast 与其他缓存和键值存储
将 Hazelcast 与 Ehcache、Guava 和 Caffeine 等其他缓存进行比较可能不是很有用。这是因为,与其他缓存不同,Hazelcast 是分布式缓存,即跨机器/JVM 传播数据。虽然 Hazelcast 在单个 JVM 上也能很好地工作,但是,它在分布式环境中更有用。
同样,将它与像 MongoDB 这样的数据库进行比较也没有多大用处。这是因为,Hazelcast 主要将数据存储在内存中(虽然它也支持写入磁盘)。因此,它提供了高 R/W 速度,但数据需要存储在内存中。
与其他数据存储不同,Hazelcast 还支持缓存/存储复杂数据类型并提供查询它们的接口。
但是,可以与Redis进行比较,它也提供类似的功能。
Hazelcast 与 Redis
在功能方面,Redis 和 Hazelcast 都非常相似。但是,以下是 Hazelcast 在 Redis 上的得分 –
-
从头开始为分布式环境构建– 与作为单机缓存开始的 Redis 不同,Hazelcast 从一开始就是为分布式环境构建的。
-
Simple cluster scale in/out – 在 Hazelcast 的情况下,维护添加或删除节点的集群非常简单,例如,添加节点是启动具有所需配置的节点的问题。删除节点需要简单地关闭节点。Hazelcast 会自动处理数据的分区等。对 Redis 进行相同的设置并执行上述操作需要更多的预防措施和手动操作。
-
支持故障转移所需的资源更少– Redis 遵循主从方法。对于故障转移,Redis 需要额外的资源来设置Redis Sentinel。如果原始主节点出现故障,这些 Sentinel 节点负责将一个从节点提升为主节点。在 Hazelcast 中,所有节点都被平等对待,一个节点的故障会被其他节点检测到。因此,节点关闭的情况非常透明地处理,而且无需任何额外的监控服务器集。
-
简单分布式计算– Hazelcast 及其EntryProcessor提供了一个简单的接口来将代码发送到数据以进行并行处理。这减少了在线数据传输。Redis 也支持这一点,但是,要实现这一点,需要了解 Lua 脚本,这会增加额外的学习曲线。
Hazelcast – 设置
Hazelcast 需要 Java 1.6 或更高版本。Hazelcast 还可以与 .NET、C++ 或其他基于 JVM 的语言(如 Scala 和 Clojure)一起使用。但是,对于本教程,我们将使用 Java 8。
在我们继续之前,以下是我们将用于本教程的项目设置。
hazelcast/ ├── com.example.demo/ │ ├── SingleInstanceHazelcastExample.java │ ├── MultiInstanceHazelcastExample.java │ ├── Server.java │ └── .... ├── pom.xml ├── target/ ├── hazelcast.xml ├── hazelcast-multicast.xml ├── ...
现在,我们可以在hazelcast 目录中创建包,即com.example.demo。然后,只需 cd 到该目录。我们将在接下来的部分中查看其他文件。
安装 Hazelcast
安装 Hazelcast 只需将 JAR 文件添加到您的构建文件中即可。POM 文件或 build.gradle 取决于您分别使用的是 Maven 还是 Gradle。
如果您使用 Gradle,将以下内容添加到 build.gradle 文件就足够了 –
dependencies {
compile "com.hazelcast:hazelcast:3.12.12”
}
教程的 POM
我们将在我们的教程中使用以下 POM –
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>1.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Demo project for Hazelcast</description>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>3.12.12</version>
</dependency>
</dependencies>
<!-- Below build plugin is not needed for Hazelcast, it is being used only to created a shaded JAR so that -->
<!-- using the output i.e. the JAR becomes simple for testing snippets in the tutorial-->
<build>
<plugins>
<plugin>
<!-- Create a shaded JAR and specify the entry point class-->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Hazelcast – 第一个应用程序
Hazelcast 可以单独运行(单节点),也可以运行多个节点组成集群。让我们首先尝试启动单个实例。
单实例
例子
现在,让我们尝试创建和使用 Hazelcast 集群的单个实例。为此,我们将创建 SingleInstanceHazelcastExample.java 文件。
package com.example.demo;
import java.util.Map;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class SingleInstanceHazelcastExample {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
System.out.println(“Hello world”);
// perform a graceful shutdown
hazelcast.shutdown();
}
}
现在让我们编译代码并执行它 –
mvn clean install java -cp target/demo-0.0.1-SNAPSHOT.jar com.example.demo.SingleInstanceHazelcastExample
输出
如果您执行上面的代码,输出将是 –
Hello World
然而,更重要的是,您还会注意到 Hazelcast 的日志行,这表示 Hazelcast 已启动。由于我们只运行此代码一次,即单个 JVM,因此我们的集群中将只有一个成员。
Jan 30, 2021 10:26:51 AM com.hazelcast.config.XmlConfigLocator
INFO: Loading 'hazelcast-default.xml' from classpath.
Jan 30, 2021 10:26:51 AM com.hazelcast.instance.AddressPicker
INFO: [LOCAL] [dev] [3.12.12] Prefer IPv4 stack is true.
Jan 30, 2021 10:26:52 AM com.hazelcast.instance.AddressPicker
INFO: [LOCAL] [dev] [3.12.12] Picked [localhost]:5701, using socket
ServerSocket[addr=/0:0:0:0:0:0:0:0,localport=5701], bind any local is true
Jan 30, 2021 10:26:52 AM com.hazelcast.system
...
Members {size:1, ver:1} [
Member [localhost]:5701 - 9b764311-9f74-40e5-8a0a-85193bce227b this
]
Jan 30, 2021 10:26:56 AM com.hazelcast.core.LifecycleService
INFO: [localhost]:5701 [dev] [3.12.12] [localhost]:5701 is STARTED
...
You will also notice log lines from Hazelcast at the end which signifies
Hazelcast was shutdown:
INFO: [localhost]:5701 [dev] [3.12.12] Hazelcast Shutdown is completed in 784 ms.
Jan 30, 2021 10:26:57 AM com.hazelcast.core.LifecycleService
INFO: [localhost]:5701 [dev] [3.12.12] [localhost]:5701 is SHUTDOWN
集群:多实例
现在,让我们创建用于多实例集群的 MultiInstanceHazelcastExample.java 文件(如下所示)。
package com.example.demo;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class MultiInstanceHazelcastExample {
public static void main(String... args) throws InterruptedException{
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//print the socket address of this member and also the size of the cluster
System.out.println(String.format("[%s]: No. of hazelcast members: %s",
hazelcast.getCluster().getLocalMember().getSocketAddress(),
hazelcast.getCluster().getMembers().size()));
// wait for the member to join
Thread.sleep(30000);
//perform a graceful shutdown
hazelcast.shutdown();
}
}
让我们在两个不同的 shell上执行以下命令–
java -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.MultiInstanceHazelcastExample
您会在第一个 shell 上注意到 Hazelcast 实例已启动并已分配成员。请注意输出的最后一行,它表示有一个成员使用端口 5701。
Jan 30, 2021 12:20:21 PM com.hazelcast.internal.cluster.ClusterService
INFO: [localhost]:5701 [dev] [3.12.12]
Members {size:1, ver:1} [
Member [localhost]:5701 - b0d5607b-47ab-47a2-b0eb-6c17c031fc2f this
]
Jan 30, 2021 12:20:21 PM com.hazelcast.core.LifecycleService
INFO: [localhost]:5701 [dev] [3.12.12] [localhost]:5701 is STARTED
[/localhost:5701]: No. of hazelcast members: 1
您会在第2 个 shell 上注意到 Hazelcast 实例已加入第一个实例。请注意输出的最后一行,它表示现在有两个成员使用端口 5702。
INFO: [localhost]:5702 [dev] [3.12.12]
Members {size:2, ver:2} [
Member [localhost]:5701 - b0d5607b-47ab-47a2-b0eb-6c17c031fc2f
Member [localhost]:5702 - 037b5fd9-1a1e-46f2-ae59-14c7b9724ec6 this
]
Jan 30, 2021 12:20:46 PM com.hazelcast.core.LifecycleService
INFO: [localhost]:5702 [dev] [3.12.12] [localhost]:5702 is STARTED
[/localhost:5702]: No. of hazelcast members: 2
Hazelcast – 配置
Hazelcast 支持编程以及基于 XML 的配置。但是,鉴于其易用性,在生产中大量使用的是 XML 配置。但是 XML 配置在内部使用 Programmatic 配置。
XML 配置
hazelcast.xml 是需要放置这些配置的地方。在以下位置搜索文件(按相同顺序),并从第一个可用位置中选择 –
-
通过系统属性将 XML 的位置传递给 JVM – Dhazelcast.config=/path/to/hazelcast.xml
-
当前工作目录中的hazelcast.xml
-
类路径中的hazelcast.xml
-
Hazelcast 提供的默认 hazelcast.xml
找到 XML 后,Hazelcast 将从 XML 文件加载所需的配置。
让我们用一个例子来试试看。在当前目录中创建一个名为 hazelcast.xml 的 XML。
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd" xmlns="http://www.hazelcast.com/schema/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <!-- name of the instance --> <instance-name>XML_Hazelcast_Instance</instance-name> </hazelcast>
目前的 XML 仅包含用于验证的 Hazelcast XML 的模式位置。但更重要的是,它包含实例名称。
例子
现在创建一个包含以下内容的 XMLConfigLoadExample.java 文件。
package com.example.demo;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class XMLConfigLoadExample {
public static void main(String... args) throws InterruptedException{
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//specified the name written in the XML file
System.out.println(String.format("Name of the instance: %s",hazelcast.getName()));
//perform a graceful shutdown
hazelcast.shutdown();
}
}
使用以下命令执行上述 Java 文件 –
java -Dhazelcast.config=hazelcast.xml -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.XMLConfigLoadExample
输出
上述命令的输出将是 –
Jan 30, 2021 1:21:41 PM com.hazelcast.config.XmlConfigLocator
INFO: Loading configuration hazelcast.xml from System property
'hazelcast.config'
Jan 30, 2021 1:21:41 PM com.hazelcast.config.XmlConfigLocator
INFO: Using configuration file at C:\Users\demo\eclipseworkspace\
hazelcast\hazelcast.xml
...
Members {size:1, ver:1} [
Member [localhost]:5701 - 3d400aed-ddb9-4e59-9429-3ab7773e7e09 this
]
Name of cluster: XML_Hazelcast_Instance
如您所见,Hazelcast 加载了配置并打印了配置中指定的名称(最后一行)。
有很多配置选项可以在 XML 中指定。可以在以下位置找到完整列表 –
随着教程的进行,我们将看到其中的一些配置。
程序化配置
如前所述,XML 配置最终是通过程序化配置完成的。因此,让我们为我们在 XML 配置中看到的相同示例尝试编程配置。为此,让我们创建包含以下内容的 ProgramaticConfigLoadExample.java 文件。
例子
package com.example.demo;
import com.hazelcast.config.Config;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class ProgramaticConfigLoadExample {
public static void main(String... args) throws InterruptedException {
Config config = new Config();
config.setInstanceName("Programtic_Hazelcast_Instance");
// initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance(config);
// specified the name written in the XML file
System.out.println(String.format("Name of the instance: %s", hazelcast.getName()));
// perform a graceful shutdown
hazelcast.shutdown();
}
}
让我们在不传递任何 hazelcast.xml 文件的情况下执行代码 –
java -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.ProgramaticConfigLoadExample
输出
上面代码的输出是 –
Name of the instance: Programtic_Hazelcast_Instance
日志记录
为了避免依赖,Hazelcast 默认使用基于 JDK 的日志记录。但它也支持通过slf4j, log4j 进行日志记录。例如,如果我们想使用 logback 为 sl4j 设置日志记录,我们可以更新 POM 以包含以下依赖项 –
<!-- contains both sl4j bindings and the logback core --> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.3</version> </dependency>
例子
定义一个配置 logback.xml 文件并将其添加到您的类路径中,例如 src/main/resources。
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
<logger name="com.hazelcast" level="error">
<appender-ref ref="STDOUT" />
</logger>
</configuration>
现在,当我们执行以下命令时,我们注意到所有关于 Hazelcast 成员创建等的元信息都没有打印出来。这是因为我们已将 Hazelcast 的日志记录级别设置为错误并要求 Hazelcast 使用 sl4j 记录器。
java -Dhazelcast.logging.type=slf4j -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.SingleInstanceHazelcastExample
输出
John
变量
写入 XML 配置文件的值可能因环境而异。例如,在生产环境中,与开发环境相比,您可以使用不同的用户名/密码连接到 Hazelcast 集群。除了维护单独的 XML 文件之外,还可以在 XML 文件中写入变量,然后通过命令行或以编程方式将这些变量传递给 Hazelcast。以下是从命令行选择实例名称的示例。
所以,这是我们带有变量 ${varname} 的 XML 文件
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<instance-name>${instance_name}</instance-name>
</hazelcast>
例子
这是我们用来打印变量值的示例 Java 代码 –
package com.example.demo;
import java.util.Map;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class XMLConfigLoadWithVariable {
public static void main(String... args) throws InterruptedException {
// initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
// specified the name written in the XML file
System.out.println(String.format("Name of the instance: %s", hazelcast.getName()));
// perform a graceful shutdown
hazelcast.shutdown();
}
}
而且,以下是命令 –
java -Dhazelcast.config=others\hazelcast.xml -Dinstance_name=dev_cluster -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.XMLConfigLoadWithVariable
输出
并且输出显示变量已被 Hazelcast 正确替换。
Name of the instance: dev_cluster
Hazelcast – 设置多节点实例
鉴于 Hazelcast 是分布式 IMDG 并且通常设置在多台机器上,因此它需要访问内部/外部网络。最重要的用例是在集群中发现 Hazelcast 节点。
Hazelcast 需要以下端口 –
-
1 个入站端口,用于从其他 Hazelcast 节点/客户端接收 ping/数据
-
n向集群的其他成员发送 ping/数据所需的出站端口数。
此节点发现以几种方式发生 –
-
组播
-
TCP/IP
-
Amazon EC2 自动发现
其中,我们将看看多播和 TCP/IP
组播
默认情况下启用多播加入机制。https://en.wikipedia.org/wiki/Multicast是一种将消息传送到组中所有节点的通信形式。这就是 Hazelcast 用来发现集群其他成员的方法。我们之前看过的所有示例都使用多播来发现成员。
例子
现在让我们显式地打开它。将以下内容保存在 hazelcast-multicast.xml 中
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<network>
<join>
<multicast enabled="true" />
</join>
</network>
</hazelcast>
然后,让我们执行以下操作 –
java -Dhazelcast.config=hazelcast-multicast.xml -cp .\target\demo-0.0.1- SNAPSHOT.jar com.example.demo.XMLConfigLoadExample
输出
在输出中,我们注意到 Hazelcast 中的以下几行,这实际上意味着使用多播加入者来发现成员。
Jan 30, 2021 5:26:15 PM com.hazelcast.instance.Node INFO: [localhost]:5701 [dev] [3.12.12] Creating MulticastJoiner
默认情况下,多播接受来自多播组中所有机器的通信。这可能是一个安全问题,这就是为什么通常对内部部署的多播通信进行防火墙设置的原因。因此,虽然多播有利于开发工作,但在生产中,最好使用基于 TCP/IP 的发现。
TCP/IP
由于组播的缺点,TCP/IP 是首选的通信方式。在 TCP/IP 的情况下,成员只能连接到已知/列出的成员。
例子
让我们使用 TCP/IP 作为发现机制。将以下内容保存在 hazelcast-tcp.xml 中
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<network>
<join>
<multicast enabled="false" />
<tcp-ip enabled="true">
<members>localhost</members>
</tcp-ip>
</join>
</network>
</hazelcast>
然后,让我们执行以下命令 –
java -Dhazelcast.config=hazelcast-tcp.xml -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.XMLConfigLoadExample
输出
该输出是继-
INFO: [localhost]:5701 [dev] [3.12.12] Creating TcpIpJoiner Jan 30, 2021 8:09:29 PM com.hazelcast.spi.impl.operationexecutor.impl.OperationExecutorImpl
上面的输出显示 TCP/IP joiner 用于加入两个成员。
如果您在两个不同的 shell 上执行以下命令 –
java '-Dhazelcast.config=hazelcast-tcp.xml' -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.MultiInstanceHazelcastExample
我们看到以下输出 –
Members {size:2, ver:2} [
Member [localhost]:5701 - 62eedeae-2701-4df0-843c-7c3655e16b0f
Member [localhost]:5702 - 859c1b46-06e6-495a-8565-7320f7738dd1 this
]
上面的输出意味着节点能够使用 TCP/IP 加入,并且都使用 localhost 作为 IP 地址。
请注意,我们可以在 XML 配置文件中指定更多 IP 或机器名称(由 DNS 解析)。
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<network>
<join>
<multicast enabled="false" />
<tcp-ip enabled="true">
<members>machine1, machine2....</members>
</tcp-ip>
</join>
</network>
</hazelcast>
Hazelcast – 数据结构
java.util.concurrent 包提供了 AtomicLong、CountDownLatch、ConcurrentHashMap 等数据结构,当您有多个线程读取/写入数据到数据结构时非常有用。但是为了提供线程安全,所有这些线程都应该在单个 JVM/机器上。
分布式数据结构有两个主要好处 –
-
更好的性能– 如果不止一台机器可以访问数据,它们都可以并行工作并在更短的时间内完成工作。
-
数据备份– 如果 JVM/机器出现故障,我们有另一个 JVM/机器保存数据
Hazelcast 提供了一种在 JVM/机器之间分布数据结构的方法。
Hazelcast – 客户端
Hazelcast 客户端是 Hazelcast 成员的轻量级客户端。Hazelcast 成员负责存储数据和分区。它们的作用类似于传统客户端-服务器模型中的服务器。
Hazelcast 客户端仅用于访问存储在集群的 Hazelcast 成员中的数据。他们不负责存储数据,也不拥有存储数据的任何所有权。
客户端有自己的生命周期,不影响 Hazelcast 成员实例。
让我们首先创建 Server.java 并运行它。
import java.util.Map;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class Server {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//create a simple map
Map<String, String> vehicleOwners = hazelcast.getMap("vehicleOwnerMap");
// add key-value to map
vehicleOwners.put("John", "Honda-9235");
// do not shutdown, let the server run
//hazelcast.shutdown();
}
}
现在,运行上面的类。
java -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.Server
为了设置客户端,我们还需要添加客户端 jar。
<dependency> <groupId>com.hazelcast</groupId> <artifactId>hazelcast-client</artifactId> <version>3.12.12</version> </dependency>
现在让我们创建 Client.java。请注意,与 Hazelcast 成员类似,客户端也可以通过编程方式或通过 XML 配置(即,通过 -Dhazelcast.client.config 或 hazelcast-client.xml)进行配置。
例子
让我们使用默认配置,这意味着我们的客户端将能够连接到本地实例。
import java.util.Map;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.core.HazelcastInstance;
public class Client {
public static void main(String... args){
//initialize hazelcast client
HazelcastInstance hzClient = HazelcastClient.newHazelcastClient();
//read from map
Map<String, String> vehicleOwners = hzClient.getMap("vehicleOwnerMap");
System.out.println(vehicleOwners.get("John"));
System.out.println("Member of cluster: " +
hzClient.getCluster().getMembers());
// perform shutdown
hzClient.getLifecycleService().shutdown();
}
}
现在,运行上面的类。
java -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.Client
输出
它将产生以下输出 –
Honda-9235 Member of cluster: [Member [localhost]:5701 - a47ec375-3105-42cd-96c7-fc5eb382e1b0]
从输出中可以看出 –
-
集群仅包含 1 个来自 Server.java 的成员。
-
客户端能够访问存储在服务器内的地图。
负载均衡
Hazelcast Client 支持使用各种算法进行负载平衡。负载平衡可确保负载在成员之间共享,并且集群的单个成员不会过载。默认负载平衡机制设置为循环。可以通过在配置中使用 loadBalancer 标记来更改相同的内容。
我们可以使用配置中的负载均衡器标签来指定负载均衡器的类型。这是选择随机选取节点的策略的示例。
<hazelcast-client xmlns="http://www.hazelcast.com/schema/client-config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hazelcast.com/schema/client-config
http://www.hazelcast.com/schema/client-config/hazelcastclient-config-4.2.xsd">
<load-balancer type="random"/>
</hazelcast-client>
故障转移
在分布式环境中,成员可以任意失败。为了支持故障转移,建议提供多个成员的地址。如果客户端可以访问任何一个成员,则足以将其发送给其他成员。参数 addressList 可以在客户端配置中指定。
例如,如果我们使用以下配置 –
<hazelcast-client xmlns="http://www.hazelcast.com/schema/client-config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.hazelcast.com/schema/client-config http://www.hazelcast.com/schema/client-config/hazelcastclient-config-4.2.xsd"> <address-list>machine1, machine2</address-list> </hazelcast-client>
即使机器 1 宕机,客户端也可以使用机器 2 访问集群的其他成员。
Hazelcast – 序列化
Hazelcast 非常适用于数据/查询分布在机器之间的环境中。这需要将数据从我们的 Java 对象序列化为可以通过网络传输的字节数组。
Hazelcast 支持各种类型的序列化。但是,让我们看看一些常用的,即Java Serialization 和Java Externalizable。
Java 序列化
例子
首先让我们看看Java序列化。比方说,我们定义了一个实现了 Serializable 接口的 Employee 类。
public class Employee implements Serializable{
private static final long serialVersionUID = 1L;
private String name;
private String department;
public Employee(String name, String department) {
super();
this.name = name;
this.department = department;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDepartment() {
return department;
}
public void setDepartment(String department) {
this.department = department;
}
@Override
public String toString() {
return "Employee [name=" + name + ", department=" + department + "]";
}
}
现在让我们编写代码将 Employee 对象添加到 Hazelcast 地图。
public class EmployeeExample {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//create a set to track employees
Map<Employee, String> employeeOwners=hazelcast.getMap("employeeVehicleMap");
Employee emp1 = new Employee("John Smith", "Computer Science");
// add employee to set
System.out.println("Serializing key-value and add to map");
employeeOwners.put(emp1, "Honda");
// check if emp1 is present in the set
System.out.println("Serializing key for searching and Deserializing
value got out of map");
System.out.println(employeeOwners.get(emp1));
// perform a graceful shutdown
hazelcast.shutdown();
}
}
输出
它将产生以下输出 –
Serializing key-value and add to map Serializing key for searching and Deserializing value got out of map Honda
这里一个非常重要的方面是,只需实现一个 Serializable 接口,我们就可以让 Hazelcast 使用 Java Serialization。另请注意,Hazelcast 存储键和值的序列化数据,而不是像 HashMap 那样将其存储在内存中。因此,Hazelcast 完成了序列化和反序列化的繁重工作。
例子
然而,这里有一个陷阱。在上述情况下,如果员工所在的部门发生变化怎么办?人还是一样。
public class EmployeeExampleFailing {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//create a set to track employees
Map<Employee, String> employeeOwners=hazelcast.getMap("employeeVehicleMap");
Employee emp1 = new Employee("John Smith", "Computer Science");
// add employee to map
System.out.println("Serializing key-value and add to map");
employeeOwners.put(emp1, "Honda");
Employee empDeptChange = new Employee("John Smith", "Electronics");
// check if emp1 is present in the set
System.out.println("Checking if employee with John Smith is present");
System.out.println(employeeOwners.containsKey(empDeptChange));
Employee empSameDept = new Employee("John Smith", "Computer Science");
System.out.println("Checking if employee with John Smith is present");
System.out.println(employeeOwners.containsKey(empSameDept));
// perform a graceful shutdown
hazelcast.shutdown();
}
}
输出
它将产生以下输出 –
Serializing key-value and add to map Checking if employee with name John Smith is present false Checking if employee with name John Smith is present true
这是因为 Hazelcast 在比较时不会反序列化键,即 Employee。它直接比较序列化密钥的字节码。因此,对所有属性具有相同值的对象将被视为相同。但是,如果这些属性的值发生变化,例如上述场景中的部门,则这两个键将被视为唯一的。
Java 可外部化
如果在上面的示例中,我们在执行键的序列化/反序列化时不关心部门的值会怎样。Hazelcast 还支持 Java Externalizable,这使我们可以控制用于序列化和反序列化的标签。
例子
让我们相应地修改我们的 Employee 类 –
public class EmplyoeeExternalizable implements Externalizable {
private static final long serialVersionUID = 1L;
private String name;
private String department;
public EmplyoeeExternalizable(String name, String department) {
super();
this.name = name;
this.department = department;
}
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
System.out.println("Deserializaing....");
this.name = in.readUTF();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
System.out.println("Serializing....");
out.writeUTF(name);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDepartment() {
return department;
}
public void setDepartment(String department) {
this.department = department;
}
@Override
public String toString() {
return "Employee [name=" + name + ", department=" + department + "]";
}
}
因此,正如您从代码中看到的,我们添加了负责序列化/反序列化的 readExternal/writeExternal 方法。鉴于我们在序列化/反序列化时对部门不感兴趣,我们排除了 readExternal/writeExternal 方法中的那些。
例子
现在,如果我们执行以下代码 –
public class EmployeeExamplePassing {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//create a set to track employees
Map<EmplyoeeExternalizable, String> employeeOwners=hazelcast.getMap("employeeVehicleMap");
EmplyoeeExternalizable emp1 = new EmplyoeeExternalizable("John Smith", "Computer Science");
// add employee to map
employeeOwners.put(emp1, "Honda");
EmplyoeeExternalizable empDeptChange = new EmplyoeeExternalizable("John Smith", "Electronics");
// check if emp1 is present in the set
System.out.println("Checking if employee with John Smith is present");
System.out.println(employeeOwners.containsKey(empDeptChange));
EmplyoeeExternalizable empSameDept = new EmplyoeeExternalizable("John Smith", "Computer Science");
System.out.println("Checking if employee with John Smith is present");
System.out.println(employeeOwners.containsKey(empSameDept));
// perform a graceful shutdown
hazelcast.shutdown();
}
}
输出
我们得到的输出是 –
Serializing.... Checking if employee with John Smith is present Serializing.... true Checking if employee with John Smith is present Serializing.... true
如输出所示,使用 Externalizable 接口,我们可以仅向 Hazelcast 提供员工姓名的序列化数据。
另请注意,Hazelcast 将我们的密钥序列化了两次 –
-
一旦存储密钥,
-
并且,第二个用于在地图中搜索给定的键。如前所述,这是因为 Hazelcast 使用序列化字节数组进行键比较。
总的来说,如果我们想更好地控制要序列化哪些属性以及如何处理它们,则使用 Externalizable 与 Serializable 相比有更多好处。
Hazelcast – Spring 集成
Hazelcast 支持一种与 Spring Boot 应用程序集成的简单方法。让我们试着通过一个例子来理解这一点。
我们将创建一个简单的 API 应用程序,它提供一个 API 来获取公司的员工信息。为此,我们将使用 Spring Boot 驱动的 RESTController 和 Hazelcast 来缓存数据。
请注意,要将 Hazelcast 集成到 Spring Boot 中,我们需要做两件事 –
-
添加 Hazelcast 作为我们项目的依赖项。
-
定义配置(静态或编程)并使其可用于 Hazelcast
让我们首先定义 POM。请注意,我们必须指定 Hazelcast JAR 才能在 Spring Boot 项目中使用它。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>hazelcast</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Demo project to explain Hazelcast integration with Spring Boot</description>
<properties>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.source>1.8</maven.compiler.source>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.0</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-all</artifactId>
<version>4.0.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
还将 hazelcast.xml 添加到 src/main/resources –
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd" xmlns="http://www.hazelcast.com/schema/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <instance-name>XML_Hazelcast_Instance</instance-name> </hazelcast>
定义一个供 Spring Boot 使用的入口点文件。确保我们指定了@EnableCaching –
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
@EnableCaching
@SpringBootApplication
public class CompanyApplication {
public static void main(String[] args) {
SpringApplication.run(CompanyApplication.class, args);
}
}
让我们定义我们的员工 POJO –
package com.example.demo;
import java.io.Serializable;
public class Employee implements Serializable{
private static final long serialVersionUID = 1L;
private int empId;
private String name;
private String department;
public Employee(Integer id, String name, String department) {
super();
this.empId = id;
this.name = name;
this.department = department;
}
public int getEmpId() {
return empId;
}
public void setEmpId(int empId) {
this.empId = empId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDepartment() {
return department;
}
public void setDepartment(String department) {
this.department = department;
}
@Override
public String toString() {
return "Employee [empId=" + empId + ", name=" + name + ", department=" + department + "]";
}
}
最后,让我们定义一个基本的 REST 控制器来访问员工 –
package com.example.demo;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/v1/")
class CompanyApplicationController{
@Cacheable(value = "employee")
@GetMapping("employee/{id}")
public Employee getSubscriber(@PathVariable("id") int id) throws
InterruptedException {
System.out.println("Finding employee information with id " + id + " ...");
Thread.sleep(5000);
return new Employee(id, "John Smith", "CS");
}
}
现在让我们通过运行命令来执行上述应用程序 –
mvn clean install mvn spring-boot:run
您会注意到该命令的输出将包含 Hazelcast 成员信息,这意味着使用 hazelcast.xml 配置为我们自动配置了 Hazelcast 实例。
Members {size:1, ver:1} [
Member [localhost]:5701 - 91b3df1d-a226-428a-bb74-6eec0a6abb14 this
]
现在让我们通过 curl 执行或使用浏览器访问 API –
curl -X GET http://localhost:8080/v1/employee/5
API 的输出将是我们的样本员工。
{
"empId": 5,
"name": "John Smith",
"department": "CS"
}
在服务器日志(即 Spring Boot 应用程序运行的地方)中,我们看到以下行 –
Finding employee information with id 5 ...
但是,请注意访问信息需要将近 5 秒(因为我们添加了睡眠)。但是如果我们再次调用 API,API 的输出是立即的。这是因为我们指定了@Cacheable 表示法。我们的第一个 API 调用的数据已使用 Hazelcast 作为后端进行缓存。
Hazelcast – 监控
Hazelcast 提供了多种方式来监控集群。我们将研究如何通过 REST API 和 JMX 进行监控。让我们首先看看 REST API。
通过 REST API 监控 Hazelcast
要通过 REST API 监控集群或成员状态的健康状况,必须启用基于 REST API 的与成员的通信。这可以通过配置来完成,也可以通过编程来完成。
让我们通过 hazelcast-monitoring.xml 中的 XML 配置启用基于 REST 的监控 –
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<instance-name>XML_Hazelcast_Instance</instance-name>
<network>
<rest-api enabled="true">
<endpoint-group name="CLUSTER_READ" enabled="true" />
<endpoint-group name="HEALTH_CHECK" enabled="true" />
</rest-api>
</network>
</hazelcast>
让我们创建一个在 Server.java 文件中无限期运行的 Hazelcast 实例 –
public class Server {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
// do not shutdown, let the server run
//hazelcast.shutdown();
}
}
现在让我们执行启动集群 –
java '-Dhazelcast.config=hazelcast-monitoring.xml' -cp .\target\demo-0.0.1- SNAPSHOT.jar com.example.demo.Server
启动后,可以通过调用 API 来了解集群的健康状况 –
http://localhost:5701/hazelcast/health
上述 API 调用的输出–
Hazelcast::NodeState=ACTIVE Hazelcast::ClusterState=ACTIVE Hazelcast::ClusterSafe=TRUE Hazelcast::MigrationQueueSize=0 Hazelcast::ClusterSize=1
这显示我们的集群中有 1 个成员并且它处于活动状态。
可以使用以下方法找到有关节点的更多详细信息,例如 IP、端口、名称:
http://localhost:5701/hazelcast/rest/cluster
上述 API 的输出 –
Members {size:1, ver:1} [
Member [localhost]:5701 - e6afefcb-6b7c-48b3-9ccb-63b4f147d79d this
]
ConnectionCount: 1
AllConnectionCount: 2
JMX 监控
Hazelcast 还支持 JMX 监控其内部嵌入的数据结构,例如 IMap、Iqueue 等。
要启用 JMX 监控,我们首先需要启用基于 JVM 的 JMX 代理。这可以通过将“-Dcom.sun.management.jmxremote”传递给 JVM 来完成。对于使用不同的端口或使用身份验证,我们可以分别使用-Dcom.sun.management.jmxremote.port、-Dcom.sun.management.jmxremote.authenticate。
除此之外,我们必须为 Hazelcast MBeans 启用 JMX。让我们通过 hazelcast-monitoring.xml 中的 XML 配置启用基于 JMX 的监控 –
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<instance-name>XML_Hazelcast_Instance</instance-name>
<properties>
<property name="hazelcast.jmx">true</property>
</properties>
</hazelcast>
让我们创建一个在 Server.java 文件中无限期运行的 Hazelcast 实例并添加一个地图 –
class Server {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//create a simple map
Map<String, String> vehicleOwners = hazelcast.getMap("vehicleOwnerMap");
// add key-value to map
vehicleOwners.put("John", "Honda-9235");
// do not shutdown, let the server run
//hazelcast.shutdown();
}
}
现在我们可以执行以下命令来启用 JMX –
java '-Dcom.sun.management.jmxremote' '-Dhazelcast.config=others\hazelcastmonitoring. xml' -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.Server
JMX 端口现在可以通过 JMX 客户端(如 jConsole、VisualVM 等)连接。
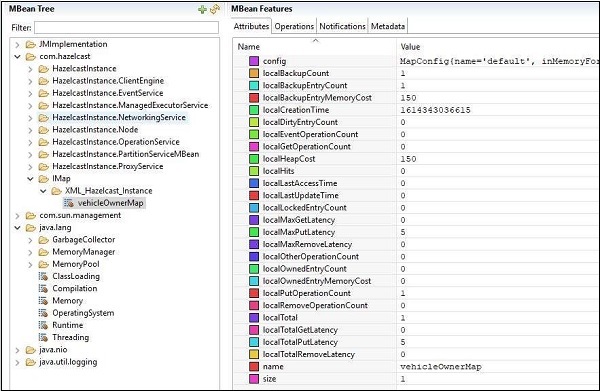
如果我们使用 jConsole 连接并查看 VehicleMap 的属性,这里是我们将获得的快照。如我们所见,地图名称为 VehicleOwnerMap,地图大小为 1。
Hazelcast – 地图缩减和聚合
MapReduce 是一种计算模型,当你有大量数据并且你需要多台机器时,即一个分布式环境来计算数据时,它对数据处理很有用。它涉及将数据“映射”成键值对,然后“归约”,即对这些键进行分组并对值执行操作。
鉴于 Hazelcast 的设计考虑到了分布式环境,因此自然而然地实现 Map-Reduce 框架。
让我们通过一个例子来看看如何做到这一点。
例如,假设我们有关于汽车(品牌和汽车编号)和汽车所有者的数据。
Honda-9235, John Hyundai-235, Alice Honda-935, Bob Mercedes-235, Janice Honda-925, Catnis Hyundai-1925, Jane
现在,我们必须弄清楚每个品牌的汽车数量,即现代、本田等。
例子
让我们尝试使用 MapReduce 找出答案 –
package com.example.demo;
import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.atomic.AtomicInteger;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.ICompletableFuture;
import com.hazelcast.core.IMap;
import com.hazelcast.mapreduce.Context;
import com.hazelcast.mapreduce.Job;
import com.hazelcast.mapreduce.JobTracker;
import com.hazelcast.mapreduce.KeyValueSource;
import com.hazelcast.mapreduce.Mapper;
import com.hazelcast.mapreduce.Reducer;
import com.hazelcast.mapreduce.ReducerFactory;
public class MapReduce {
public static void main(String[] args) throws ExecutionException,
InterruptedException {
try {
// create two Hazelcast instances
HazelcastInstance hzMember = Hazelcast.newHazelcastInstance();
Hazelcast.newHazelcastInstance();
IMap<String, String> vehicleOwnerMap=hzMember.getMap("vehicleOwnerMap");
vehicleOwnerMap.put("Honda-9235", "John");
vehicleOwnerMap.putc"Hyundai-235", "Alice");
vehicleOwnerMap.put("Honda-935", "Bob");
vehicleOwnerMap.put("Mercedes-235", "Janice");
vehicleOwnerMap.put("Honda-925", "Catnis");
vehicleOwnerMap.put("Hyundai-1925", "Jane");
KeyValueSource<String, String> kvs=KeyValueSource.fromMap(vehicleOwnerMap);
JobTracker tracker = hzMember.getJobTracker("vehicleBrandJob");
Job<String, String> job = tracker.newJob(kvs);
ICompletableFuture<Map<String, Integer>> myMapReduceFuture =
job.mapper(new BrandMapper())
.reducer(new BrandReducerFactory()).submit();
Map<String, Integer&g result = myMapReduceFuture.get();
System.out.println("Final output: " + result);
} finally {
Hazelcast.shutdownAll();
}
}
private static class BrandMapper implements Mapper<String, String, String, Integer> {
@Override
public void map(String key, String value, Context<String, Integer>
context) {
context.emit(key.split("-", 0)[0], 1);
}
}
private static class BrandReducerFactory implements ReducerFactory<String, Integer, Integer> {
@Override
public Reducer<Integer, Integer> newReducer(String key) {
return new BrandReducer();
}
}
private static class BrandReducer extends Reducer<Integer, Integer> {
private AtomicInteger count = new AtomicInteger(0);
@Override
public void reduce(Integer value) {
count.addAndGet(value);
}
@Override
public Integer finalizeReduce() {
return count.get();
}
}
}
让我们试着理解这段代码 –
- 我们创建 Hazelcast 成员。在示例中,我们只有一个成员,但也可以有多个成员。
-
我们使用虚拟数据创建地图并从中创建键值存储。
-
我们创建一个 Map-Reduce 作业并要求它使用键值存储作为数据。
-
然后我们将作业提交到集群并等待完成。
-
映射器创建一个键,即从原始键中提取品牌信息并将值设置为 1,然后将该信息作为 KV 发送给化简器。
-
reducer 只是简单地根据键(即品牌名称)对值进行求和,对数据进行分组。
输出
代码的输出 –
Final output: {Mercedes=1, Hyundai=2, Honda=3}
Hazelcast – 集合监听器
Hazelcast 支持在给定集合(例如队列、集合、列表等)更新时添加侦听器。典型事件包括添加条目和删除条目。
让我们通过一个例子来看看如何实现一个集合监听器。所以,假设我们想要实现一个监听器来跟踪集合中元素的数量。
例子
所以,让我们首先实现生产者 –
public class SetTimedProducer{
public static void main(String... args) throws IOException,
InterruptedException {
//initialize hazelcast instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
Thread.sleep(5000);
// create a set
ISet<String> hzFruits = hazelcast.getSet("fruits");
hzFruits.add("Mango");
Thread.sleep(2000);
hzFruits.add("Apple");
Thread.sleep(2000);
hzFruits.add("Banana");
System.exit(0);
}
}
现在让我们实现监听器 –
package com.example.demo;
import java.io.IOException;
import com.hazelcast.core.ISet;
import com.hazelcast.core.ItemEvent;
import com.hazelcast.core.ItemListener;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class SetListener{
public static void main(String... args) throws IOException, InterruptedException {
//initialize hazelcast instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
// create a set
ISet<String> hzFruits = hazelcast.getSet("fruits");
ItemListener<String> listener = new FruitListener<String>();
hzFruits.addItemListener(listener, true);
System.exit(0);
}
private static class FruitListener<String> implements ItemListener<String> {
private int count = 0;
@Override
public void itemAdded(ItemEvent<String> item) {
System.out.println("item added" + item);
count ++;
System.out.println("Total elements" + count);
}
@Override
public void itemRemoved(ItemEvent<String> item) {
count --;
}
}
}
我们将首先运行生产者 –
java -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.SetTimedProducer
然后,我们运行侦听器并让它无限期地运行 –
java -cp .\target\demo-0.0.1-SNAPSHOT.jar com.example.demo.SetListener
输出
监听器的输出如下 –
item added: ItemEvent{
event=ADDED, item=Mango, member=Member [localhost]:5701-c28a60b7-3259-44bf-8793-54063d244394 this}
Total elements: 1
item added: ItemEvent{
event=ADDED, item=Apple, member=Member [localhost]:5701-c28a60b7-3259-44bf-8793-54063d244394 this}
Total elements: 2
item added: ItemEvent{
event=ADDED, item=Banana, member=Member [localhost]:5701-c28a60b7-3259-44bf-8793-54063d244394 this}
Total elements: 3
对 hzFruits.addItemListener(listener, true) 的调用告诉 Hazelcast 提供成员信息。如果设置为 false,我们只会收到添加/删除条目的通知。这有助于避免需要序列化和反序列化条目以使其可供侦听器访问。
Hazelcast – 常见陷阱和性能提示
单机上的 Hazelcast 队列
Hazelcast 队列存储在单个成员上(以及不同机器上的备份)。这实际上意味着队列可以容纳可以在一台机器上容纳的尽可能多的项目。因此,队列容量不会通过添加更多成员来扩展。加载比机器在队列中可以处理的数据更多的数据可能会导致机器崩溃。
使用 Map 的 set 方法而不是 put
如果我们使用 IMap 的 put(key, newValue),Hazelcast 会返回 oldValue。这意味着在反序列化上花费了额外的计算和时间。这还包括从网络发送的更多数据。相反,如果我们对 oldValue 不感兴趣,我们可以使用返回 void 的 set(key, value)。
让我们看看如何存储和注入对 Hazelcast 结构的引用。下面的代码创建了一张名为“stock”的地图,并在一个地方添加了 Mango,在另一个地方添加了 Apple。
//initialize hazelcast instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
// create a map
IMap<String, String> hzStockTemp = hazelcast.getMap("stock");
hzStock.put("Mango", "4");
IMap<String, String> hzStockTemp2 = hazelcast.getMap("stock");
hzStock.put("Apple", "3");
然而,这里的问题是我们使用了两次 getMap(“stock”) 。尽管此调用在单节点环境中似乎无害,但它会在集群环境中造成缓慢。函数调用 getMap() 涉及到集群其他成员的网络往返。
因此,建议我们将地图的引用存储在本地,并在对地图进行操作时使用该引用。例如 –
// create a map
IMap<String, String> hzStock = hazelcast.getMap("stock");
hzStock.put("Mango", "4");
hzStock.put("Apple", "3");
Hazelcast 使用序列化数据进行对象比较
正如我们在前面的例子中看到的,非常重要的是要注意 Hazelcast 在比较键时不使用反序列化对象。因此,它无法访问在我们的 equals/hashCode 方法中编写的代码。根据 Hazelcast 的说法,如果两个 Java 对象的所有属性的值都相同,则键值相等。
使用监控
在大型分布式系统中,监控起着非常重要的作用。使用 REST API 和 JMX 进行监控对于采取主动措施而不是被动措施非常重要。
同构集群
Hazelcast 假设所有机器都是平等的,即所有机器都拥有相同的资源。但是,如果我们的集群包含一台功能较弱的机器,例如,较少的内存、较低的 CPU 能力等,那么如果在该机器上进行计算,就会造成速度缓慢。最糟糕的是,较弱的机器可能会耗尽资源,从而导致级联故障。所以,Hazelcast成员拥有同等的资源实力是必要的。
