Hive – 快速指南
Hive – 快速指南
蜂巢 – 简介
术语“大数据”用于包含大量、高速和日益增加的各种数据的大型数据集的集合。使用传统的数据管理系统,很难处理大数据。因此,Apache 软件基金会引入了一个名为 Hadoop 的框架来解决大数据管理和处理挑战。
Hadoop
Hadoop 是一个开源框架,用于在分布式环境中存储和处理大数据。它包含两个模块,一个是 MapReduce,另一个是 Hadoop 分布式文件系统 (HDFS)。
-
MapReduce:它是一种并行编程模型,用于在大型商品硬件集群上处理大量结构化、半结构化和非结构化数据。
-
HDFS: Hadoop分布式文件系统是Hadoop框架的一部分,用于存储和处理数据集。它提供了一个容错的文件系统,可以在商品硬件上运行。
Hadoop 生态系统包含不同的子项目(工具),例如 Sqoop、Pig 和 Hive,用于帮助 Hadoop 模块。
-
Sqoop:用于在HDFS和RDBMS之间来回导入和导出数据。
-
Pig:它是一个过程语言平台,用于为 MapReduce 操作开发脚本。
-
Hive:是一个用来开发SQL类型脚本做MapReduce操作的平台。
注意:有多种方式可以执行 MapReduce 操作:
- 传统方法使用 Java MapReduce 程序来处理结构化、半结构化和非结构化数据。
- MapReduce 使用 Pig 处理结构化和半结构化数据的脚本方法。
- MapReduce 使用 Hive 处理结构化数据的 Hive 查询语言(HiveQL 或 HQL)。
什么是蜂巢
Hive 是一个数据仓库基础设施工具,用于在 Hadoop 中处理结构化数据。它驻留在 Hadoop 之上以汇总大数据,并使查询和分析变得容易。
最初 Hive 是由 Facebook 开发的,后来 Apache 软件基金会接受了它,并将其进一步开发为名为 Apache Hive 的开源。它被不同的公司使用。例如,亚马逊在 Amazon Elastic MapReduce 中使用它。
蜂巢不是
- 关系型数据库
- 联机事务处理 (OLTP) 的设计
- 一种用于实时查询和行级更新的语言
蜂巢的特点
- 它将模式存储在数据库中并将处理后的数据存储到 HDFS。
- 它是为 OLAP 设计的。
- 它提供用于查询的 SQL 类型语言,称为 HiveQL 或 HQL。
- 它熟悉、快速、可扩展和可扩展。
Hive 的架构
下面的组件图描述了 Hive 的架构:
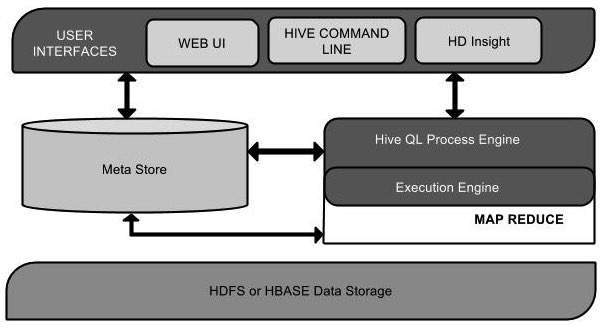
此组件图包含不同的单元。下表描述了每个单元:
| Unit Name | 手术 |
|---|---|
| User Interface | Hive 是一种数据仓库基础架构软件,可以创建用户和 HDFS 之间的交互。Hive 支持的用户界面是 Hive Web UI、Hive 命令行和 Hive HD Insight(在 Windows 服务器中)。 |
| Meta Store | Hive 选择各自的数据库服务器来存储表、数据库、表中的列、它们的数据类型和 HDFS 映射的模式或元数据。 |
| HiveQL Process Engine | HiveQL 类似于 SQL,用于查询 Metastore 上的架构信息。它是 MapReduce 程序传统方法的替代品之一。我们可以为 MapReduce 作业编写一个查询并对其进行处理,而不是用 Java 编写 MapReduce 程序。 |
| Execution Engine | HiveQL 流程引擎和 MapReduce 的结合部分是 Hive 执行引擎。执行引擎处理查询并生成与 MapReduce 结果相同的结果。它使用 MapReduce 的风格。 |
| HDFS or HBASE | Hadoop 分布式文件系统或 HBASE 是将数据存储到文件系统中的数据存储技术。 |
Hive 的工作
下图描述了 Hive 和 Hadoop 之间的工作流。
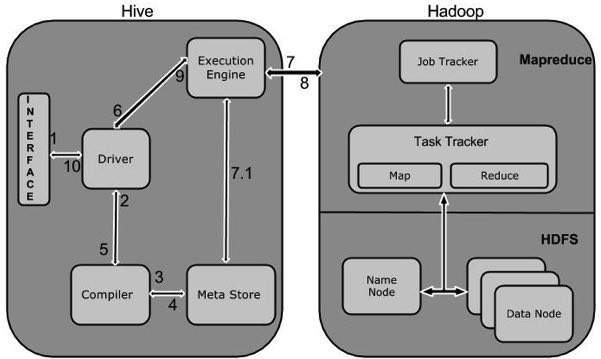
下表定义了 Hive 如何与 Hadoop 框架交互:
| Step No. | 手术 |
|---|---|
| 1 | 执行查询
命令行或Web UI 等Hive 接口向Driver(任何数据库驱动程序,如JDBC、ODBC 等)发送查询以执行。 |
| 2 | 获取计划
驱动程序借助解析查询的查询编译器来检查语法和查询计划或查询的要求。 |
| 3 | 获取元数据
编译器向 Metastore(任何数据库)发送元数据请求。 |
| 4 | 发送元数据
Metastore 将元数据作为对编译器的响应发送。 |
| 5 | 发送计划
编译器检查需求并将计划重新发送给驱动程序。到这里,一个查询的解析和编译就完成了。 |
| 6 | 执行计划
驱动程序将执行计划发送到执行引擎。 |
| 7 | 执行作业
在内部,执行作业的过程是一个 MapReduce 作业。执行引擎将作业发送到 Name 节点中的 JobTracker,并将该作业分配给 Data 节点中的 TaskTracker。在这里,查询执行 MapReduce 作业。 |
| 7.1 | 元数据操作
同时在执行过程中,执行引擎可以通过Metastore来执行元数据操作。 |
| 8 | 获取结果
执行引擎从数据节点接收结果。 |
| 9 | 发送结果
执行引擎将这些结果值发送给驱动程序。 |
| 10 | 发送结果
驱动程序将结果发送到 Hive 接口。 |
Hive – 安装
Hive、Pig、HBase等所有Hadoop子项目都支持Linux操作系统。因此,您需要安装任何 Linux 风格的操作系统。Hive安装执行以下简单步骤:
步骤 1:验证 JAVA 安装
在安装 Hive 之前,必须在您的系统上安装 Java。让我们使用以下命令验证 java 安装:
$ java –version
如果您的系统上已经安装了 Java,您将看到以下响应:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系统中未安装 java,请按照下面给出的步骤安装 java。
安装 Java
步骤一:
通过访问以下链接下载 java (JDK <最新版本> – X64.tar.gz) http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html。
然后 jdk-7u71-linux-x64.tar.gz 将被下载到您的系统上。
第二步:
通常,您会在下载文件夹中找到下载的 java 文件。验证它并使用以下命令提取 jdk-7u71-linux-x64.gz 文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
第三步:
要使所有用户都可以使用 java,您必须将其移动到“/usr/local/”位置。打开root,输入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
第四步:
要设置 PATH 和 JAVA_HOME 变量,请将以下命令添加到 ~/.bashrc 文件中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
现在使用命令 java -version 从终端验证安装,如上所述。
步骤 2:验证 Hadoop 安装
在安装 Hive 之前,必须在您的系统上安装 Hadoop。让我们使用以下命令验证 Hadoop 安装:
$ hadoop version
如果您的系统上已经安装了 Hadoop,那么您将收到以下响应:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果您的系统上未安装 Hadoop,请继续执行以下步骤:
下载 Hadoop
使用以下命令从 Apache Software Foundation 下载并提取 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
以伪分布式模式安装Hadoop
以下步骤用于以伪分布式模式安装 Hadoop 2.4.1。
第 I 步:设置 Hadoop
您可以通过将以下命令附加到~/.bashrc文件来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
现在将所有更改应用到当前运行的系统中。
$ source ~/.bashrc
第二步:Hadoop配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。您需要根据您的 Hadoop 基础架构对这些配置文件进行适当的更改。
$ cd $HADOOP_HOME/etc/hadoop
为了使用 java 开发 Hadoop 程序,您必须通过将JAVA_HOME值替换为您系统中 java 的位置来重置hadoop-env.sh文件中的 java 环境变量。
export JAVA_HOME=/usr/local/jdk1.7.0_71
下面给出了您必须编辑以配置 Hadoop 的文件列表。
核心站点.xml
该芯-的site.xml文件包含的信息,如用于Hadoop的实例,分配给文件系统的存储器,存储器限制用于存储所述数据的端口号,以及读/写缓冲器的大小。
打开 core-site.xml 并在 <configuration> 和 </configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
在HDFS-的site.xml文件中包含的信息,如复制数据的值,名称节点的路径,你的本地文件系统的数据管理部路径。这意味着您要存储 Hadoop 基础设施的地方。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件并在此文件的 <configuration>、</configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value >
</property>
</configuration>
注意:在上述文件中,所有属性值都是用户定义的,您可以根据您的 Hadoop 基础架构进行更改。
纱线站点.xml
该文件用于将 yarn 配置到 Hadoop 中。打开 yarn-site.xml 文件并在此文件的 <configuration>、</configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
该文件用于指定我们使用的 MapReduce 框架。默认情况下,Hadoop 包含一个yarn-site.xml 模板。首先,您需要使用以下命令将文件从 mapred-site,xml.template 复制到 mapred-site.xml 文件。
$ cp mapred-site.xml.template mapred-site.xml
打开mapred-site.xml文件并在此文件的 <configuration>、</configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
第 I 步:名称节点设置
使用命令“hdfs namenode -format”设置namenode,如下所示。
$ cd ~ $ hdfs namenode -format
预期结果如下。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
第二步:验证Hadoop dfs
以下命令用于启动dfs。执行此命令将启动您的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
第三步:验证纱线脚本
以下命令用于启动纱线脚本。执行此命令将启动您的纱线守护进程。
$ start-yarn.sh
预期输出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
第四步:在浏览器上访问Hadoop
访问 Hadoop 的默认端口号是 50070。使用以下 URL 在浏览器上获取 Hadoop 服务。
http://localhost:50070/
第五步:验证集群的所有应用程序
访问集群所有应用的默认端口号是8088。使用下面的url访问这个服务。
http://localhost:8088/
第 3 步:下载 Hive
我们在本教程中使用 hive-0.14.0。您可以通过访问以下链接下载它http://apache.petsads.us/hive/hive-0.14.0/。让我们假设它被下载到 /Downloads 目录中。在这里,我们为本教程下载名为“apache-hive-0.14.0-bin.tar.gz”的 Hive 存档。以下命令用于验证下载:
$ cd Downloads $ ls
成功下载后,您会看到以下响应:
apache-hive-0.14.0-bin.tar.gz
第 4 步:安装 Hive
在您的系统上安装 Hive 需要执行以下步骤。让我们假设 Hive 存档已下载到 /Downloads 目录中。
提取和验证 Hive 存档
以下命令用于验证下载并提取 hive 存档:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ ls
成功下载后,您会看到以下响应:
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz
将文件复制到 /usr/local/hive 目录
我们需要从超级用户“su -”复制文件。以下命令用于将文件从解压目录复制到 /usr/local/hive 目录。
$ su - passwd: # cd /home/user/Download # mv apache-hive-0.14.0-bin /usr/local/hive # exit
为 Hive 设置环境
您可以通过将以下几行附加到~/.bashrc文件来设置 Hive 环境:
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:. export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
以下命令用于执行 ~/.bashrc 文件。
$ source ~/.bashrc
第 5 步:配置 Hive
要使用 Hadoop 配置 Hive,您需要编辑hive-env.sh文件,该文件位于$HIVE_HOME/conf目录中。以下命令重定向到 Hive配置文件夹并复制模板文件:
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.sh
通过附加以下行来编辑hive-env.sh文件:
export HADOOP_HOME=/usr/local/hadoop
Hive 安装成功完成。现在您需要一个外部数据库服务器来配置 Metastore。我们使用 Apache Derby 数据库。
步骤 6:下载并安装 Apache Derby
按照下面给出的步骤下载和安装 Apache Derby:
下载 Apache Derby
以下命令用于下载 Apache Derby。下载需要一些时间。
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
以下命令用于验证下载:
$ ls
成功下载后,您会看到以下响应:
db-derby-10.4.2.0-bin.tar.gz
提取和验证 Derby 存档
以下命令用于提取和验证 Derby 存档:
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz $ ls
成功下载后,您会看到以下响应:
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz
将文件复制到 /usr/local/derby 目录
我们需要从超级用户“su -”复制。以下命令用于将文件从解压目录复制到 /usr/local/derby 目录:
$ su - passwd: # cd /home/user # mv db-derby-10.4.2.0-bin /usr/local/derby # exit
为德比设置环境
您可以通过将以下几行附加到~/.bashrc文件来设置 Derby 环境:
export DERBY_HOME=/usr/local/derby export PATH=$PATH:$DERBY_HOME/bin Apache Hive 18 export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
以下命令用于执行~/.bashrc文件:
$ source ~/.bashrc
创建一个目录来存储 Metastore
在 $DERBY_HOME 目录中创建一个名为 data 的目录来存储 Metastore 数据。
$ mkdir $DERBY_HOME/data
Derby 安装和环境设置现已完成。
第七步:配置Hive的Metastore
配置 Metastore 意味着向 Hive 指定存储数据库的位置。您可以通过编辑 $HIVE_HOME/conf 目录中的 hive-site.xml 文件来完成此操作。首先,使用以下命令复制模板文件:
$ cd $HIVE_HOME/conf $ cp hive-default.xml.template hive-site.xml
编辑hive-site.xml并在 <configuration> 和 </configuration> 标记之间附加以下行:
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby://localhost:1527/metastore_db;create=true </value> <description>JDBC connect string for a JDBC metastore </description> </property>
创建一个名为 jpox.properties 的文件并将以下几行添加到其中:
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl org.jpox.autoCreateSchema = false org.jpox.validateTables = false org.jpox.validateColumns = false org.jpox.validateConstraints = false org.jpox.storeManagerType = rdbms org.jpox.autoCreateSchema = true org.jpox.autoStartMechanismMode = checked org.jpox.transactionIsolation = read_committed javax.jdo.option.DetachAllOnCommit = true javax.jdo.option.NontransactionalRead = true javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true javax.jdo.option.ConnectionUserName = APP javax.jdo.option.ConnectionPassword = mine
步骤 8:验证 Hive 安装
在运行 Hive 之前,您需要在 HDFS 中创建/tmp文件夹和单独的 Hive 文件夹。在这里,我们使用/user/hive/warehouse文件夹。您需要为这些新创建的文件夹设置写权限,如下所示:
chmod g+w
现在在验证 Hive 之前将它们设置在 HDFS 中。使用以下命令:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
以下命令用于验证 Hive 安装:
$ cd $HIVE_HOME $ bin/hive
成功安装 Hive 后,您将看到以下响应:
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/hive-log4j.properties Hive history file=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt …………………. hive>
执行以下示例命令以显示所有表:
hive> show tables; OK Time taken: 2.798 seconds hive>
Hive – 数据类型
本章将带您了解 Hive 中涉及表创建的不同数据类型。Hive中所有的数据类型分为四种,如下:
- 列类型
- 文字
- 空值
- 复杂类型
列类型
列类型用作 Hive 的列数据类型。它们如下:
积分类型
可以使用整数数据类型 INT 指定整数类型数据。当数据范围超过INT的范围时,需要使用BIGINT,如果数据范围小于INT,则使用SMALLINT。TINYINT 比 SMALLINT 小。
下表描述了各种 INT 数据类型:
| Type | 后缀 | 例子 |
|---|---|---|
| TINYINT | 是 | 10年 |
| SMALLINT | 秒 | 10S |
| INT | —— | 10 |
| BIGINT | 升 | 10L |
字符串类型
可以使用单引号 (‘ ‘) 或双引号 (” “) 指定字符串类型数据类型。它包含两种数据类型:VARCHAR 和 CHAR。Hive 遵循 C 类型转义字符。
下表描述了各种 CHAR 数据类型:
| Data Type | 长度 |
|---|---|
| VARCHAR | 1 至 65355 |
| CHAR | 255 |
时间戳
它支持具有可选纳秒精度的传统 UNIX 时间戳。它支持 java.sql.Timestamp 格式“YYYY-MM-DD HH:MM:SS.fffffffff”和格式“yyyy-mm-dd hh:mm:ss.ffffffffff”。
日期
DATE 值以年/月/日格式以 {{YYYY-MM-DD}} 的形式描述。
小数点
Hive 中的 DECIMAL 类型与 Java 的 Big Decimal 格式相同。它用于表示不可变的任意精度。语法和示例如下:
DECIMAL(precision, scale) decimal(10,0)
联合类型
Union 是异构数据类型的集合。您可以使用create union创建实例。语法和示例如下:
UNIONTYPE<int, double, array<string>, struct<a:int,b:string>>
{0:1}
{1:2.0}
{2:["three","four"]}
{3:{"a":5,"b":"five"}}
{2:["six","seven"]}
{3:{"a":8,"b":"eight"}}
{0:9}
{1:10.0}
文字
Hive 中使用了以下文字:
浮点类型
浮点类型只不过是带小数点的数字。通常,这种类型的数据由 DOUBLE 数据类型组成。
十进制类型
Decimal 类型的数据只不过是比 DOUBLE 数据类型范围更大的浮点值。十进制类型的范围大约是-10-308 到 10308.
空值
缺失值由特殊值 NULL 表示。
复杂类型
Hive 复杂数据类型如下:
数组
Hive 中的数组的使用方式与它们在 Java 中的使用方式相同。
语法:ARRAY<data_type>
地图
Hive 中的地图类似于 Java 地图。
语法:MAP<primitive_type, data_type>
结构
Hive 中的结构类似于使用带有注释的复杂数据。
语法:STRUCT<col_name : data_type [COMMENT col_comment], …>
Hive – 创建数据库
Hive 是一种数据库技术,可以定义数据库和表来分析结构化数据。结构化数据分析的主题是以表格的方式存储数据,并通过查询对其进行分析。本章介绍如何创建 Hive 数据库。Hive 包含一个名为default的默认数据库。
创建数据库语句
Create Database 是用于在 Hive 中创建数据库的语句。Hive 中的数据库是一个命名空间或一组表。该语句的语法如下:
CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name>
这里,IF NOT EXISTS 是一个可选子句,它通知用户同名的数据库已经存在。我们可以在此命令中使用 SCHEMA 代替 DATABASE。执行以下查询以创建名为userdb的数据库:
hive> CREATE DATABASE [IF NOT EXISTS] userdb;
或者
hive> CREATE SCHEMA userdb;
以下查询用于验证数据库列表:
hive> SHOW DATABASES; default userdb
JDBC程序
下面给出了创建数据库的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet; 4. CREATE DATABASE
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateDb {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("CREATE DATABASE userdb");
System.out.println(“Database userdb created successfully.”);
con.close();
}
}
将程序保存在名为 HiveCreateDb.java 的文件中。以下命令用于编译和执行该程序。
$ javac HiveCreateDb.java $ java HiveCreateDb
输出:
Database userdb created successfully.
Hive – 删除数据库
本章介绍如何在 Hive 中删除数据库。SCHEMA 和 DATABASE 的用法相同。
删除数据库语句
Drop Database 是删除所有表并删除数据库的语句。其语法如下:
DROP DATABASE StatementDROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
以下查询用于删除数据库。让我们假设数据库名称是userdb。
hive> DROP DATABASE IF EXISTS userdb;
以下查询使用CASCADE删除数据库。这意味着在删除数据库之前删除相应的表。
hive> DROP DATABASE IF EXISTS userdb CASCADE;
以下查询使用SCHEMA删除数据库。
hive> DROP SCHEMA userdb;
此条款是在 Hive 0.6 中添加的。
JDBC程序
下面给出了删除数据库的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager; 5. DROP DATABASE
public class HiveDropDb {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("DROP DATABASE userdb");
System.out.println(“Drop userdb database successful.”);
con.close();
}
}
将程序保存在名为 HiveDropDb.java 的文件中。下面给出了编译和执行这个程序的命令。
$ javac HiveDropDb.java $ java HiveDropDb
输出:
Drop userdb database successful.
Hive – 创建表
本章介绍如何创建表以及如何向其中插入数据。在 HIVE 中创建表的约定与使用 SQL 创建表非常相似。
创建表语句
Create Table 是用于在 Hive 中创建表的语句。语法和示例如下:
句法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
例子
让我们假设您需要使用CREATE TABLE语句创建一个名为employee 的表。下表列出了员工表中的字段及其数据类型:
| Sr.No | 字段名称 | 数据类型 |
|---|---|---|
| 1 | 开斋节 | 整数 |
| 2 | 名称 | 细绳 |
| 3 | 薪水 | 漂浮 |
| 4 | 指定 | 细绳 |
以下数据是注释、行格式字段,例如字段终止符、行终止符和存储文件类型。
COMMENT ‘Employee details’ FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED IN TEXT FILE
以下查询使用上述数据创建名为employee的表。
hive> CREATE TABLE IF NOT EXISTS employee ( eid int, name String, > salary String, destination String) > COMMENT ‘Employee details’ > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ‘\t’ > LINES TERMINATED BY ‘\n’ > STORED AS TEXTFILE;
如果添加选项 IF NOT EXISTS,则 Hive 会在表已存在的情况下忽略该语句。
成功创建表后,您将看到以下响应:
OK Time taken: 5.905 seconds hive>
JDBC程序
举例说明创建表的JDBC程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateTable {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("CREATE TABLE IF NOT EXISTS "
+" employee ( eid int, name String, "
+" salary String, destignation String)"
+" COMMENT ‘Employee details’"
+" ROW FORMAT DELIMITED"
+" FIELDS TERMINATED BY ‘\t’"
+" LINES TERMINATED BY ‘\n’"
+" STORED AS TEXTFILE;");
System.out.println(“ Table employee created.”);
con.close();
}
}
将程序保存在名为 HiveCreateDb.java 的文件中。以下命令用于编译和执行该程序。
$ javac HiveCreateDb.java $ java HiveCreateDb
输出
Table employee created.
加载数据语句
一般在SQL中建表后,我们可以使用Insert语句插入数据。但是在 Hive 中,我们可以使用 LOAD DATA 语句插入数据。
在向 Hive 中插入数据时,最好使用 LOAD DATA 存储批量记录。加载数据有两种方式:一种是从本地文件系统加载数据,另一种是从Hadoop文件系统加载数据。
语法
加载数据的语法如下:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- LOCAL 是指定本地路径的标识符。它是可选的。
- OVERWRITE 是可选的,用于覆盖表中的数据。
- 分区是可选的。
例子
我们将以下数据插入到表中。它被命名为一个文本文件sample.txt的在/ home / user的目录。
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Krian 40000 Hr Admin 1205 Kranthi 30000 Op Admin
以下查询将给定的文本加载到表中。
hive> LOAD DATA LOCAL INPATH '/home/user/sample.txt' > OVERWRITE INTO TABLE employee;
成功下载后,您会看到以下响应:
OK Time taken: 15.905 seconds hive>
JDBC程序
下面给出的是将给定数据加载到表中的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveLoadData {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("LOAD DATA LOCAL INPATH '/home/user/sample.txt'"
+"OVERWRITE INTO TABLE employee;");
System.out.println("Load Data into employee successful");
con.close();
}
}
将程序保存在名为 HiveLoadData.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveLoadData.java $ java HiveLoadData
输出:
Load Data into employee successful
Hive – 更改表
本章介绍如何更改表的属性,例如更改其表名、更改列名、添加列以及删除或替换列。
更改表语句
它用于更改 Hive 中的表。
句法
该语句根据我们希望在表中修改的属性采用以下任何一种语法。
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
重命名为…语句
以下查询将表从employee重命名为emp。
hive> ALTER TABLE employee RENAME TO emp;
JDBC程序
重命名表的JDBC程序如下。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterRenameTo {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee RENAME TO emp;");
System.out.println("Table Renamed Successfully");
con.close();
}
}
将程序保存在名为 HiveAlterRenameTo.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveAlterRenameTo.java $ java HiveAlterRenameTo
输出:
Table renamed successfully.
变更声明
下表包含员工表的字段,并显示要更改的字段(以粗体显示)。
| Field Name | 从数据类型转换 | 更改字段名称 | 转换为数据类型 |
|---|---|---|---|
| eid | 整数 | 开斋节 | 整数 |
| name | 细绳 | 名称 | 细绳 |
| salary | 漂浮 | 薪水 | 双倍的 |
| designation | 细绳 | 指定 | 细绳 |
以下查询使用上述数据重命名列名和列数据类型:
hive> ALTER TABLE employee CHANGE name ename String; hive> ALTER TABLE employee CHANGE salary salary Double;
JDBC程序
下面给出了更改列的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterChangeColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee CHANGE name ename String;");
stmt.executeQuery("ALTER TABLE employee CHANGE salary salary Double;");
System.out.println("Change column successful.");
con.close();
}
}
将程序保存在名为 HiveAlterChangeColumn.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveAlterChangeColumn.java $ java HiveAlterChangeColumn
输出:
Change column successful.
添加列语句
以下查询将名为 dept 的列添加到员工表中。
hive> ALTER TABLE employee ADD COLUMNS ( > dept STRING COMMENT 'Department name');
JDBC程序
下面给出了向表中添加列的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterAddColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee ADD COLUMNS "
+" (dept STRING COMMENT 'Department name');");
System.out.prinln("Add column successful.");
con.close();
}
}
将程序保存在名为 HiveAlterAddColumn.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveAlterAddColumn.java $ java HiveAlterAddColumn
输出:
Add column successful.
替换语句
以下查询从employee表中删除所有列并将其替换为emp和name列:
hive> ALTER TABLE employee REPLACE COLUMNS ( > eid INT empid Int, > ename STRING name String);
JDBC程序
下面给出了用empid替换eid列和用name替换ename列的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterReplaceColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee REPLACE COLUMNS "
+" (eid INT empid Int,"
+" ename STRING name String);");
System.out.println(" Replace column successful");
con.close();
}
}
将程序保存在名为 HiveAlterReplaceColumn.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveAlterReplaceColumn.java $ java HiveAlterReplaceColumn
输出:
Replace column successful.
Hive – 删除表
本章介绍如何在 Hive 中删除表。当您从 Hive Metastore 中删除表时,它会删除表/列数据及其元数据。可以是普通表(存储在Metastore中)也可以是外部表(存储在本地文件系统中);Hive 以相同的方式对待两者,而不管它们的类型。
删除表语句
语法如下:
DROP TABLE [IF EXISTS] table_name;
以下查询删除名为employee的表:
hive> DROP TABLE IF EXISTS employee;
成功执行查询后,您将看到以下响应:
OK Time taken: 5.3 seconds hive>
JDBC程序
以下 JDBC 程序删除员工表。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveDropTable {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("DROP TABLE IF EXISTS employee;");
System.out.println("Drop table successful.");
con.close();
}
}
将程序保存在名为 HiveDropTable.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveDropTable.java $ java HiveDropTable
输出:
Drop table successful
以下查询用于验证表列表:
hive> SHOW TABLES; emp ok Time taken: 2.1 seconds hive>
Hive – 分区
Hive 将表组织成分区。它是一种根据日期、城市和部门等分区列的值将表划分为相关部分的方法。使用分区,可以很容易地查询到一部分数据。
表或分区被细分为桶,为数据提供额外的结构,可用于更有效的查询。分桶基于表的某些列的哈希函数值工作。
例如,名为Tab1的表包含员工数据,例如 id、name、dept 和 yoj(即加入年份)。假设您需要检索 2012 年加入的所有员工的详细信息。查询在整个表中搜索所需信息。但是,如果您将员工数据按年份分区并将其存储在单独的文件中,则会减少查询处理时间。以下示例显示了如何对文件及其数据进行分区:
以下文件包含员工数据表。
/tab1/employeedata/file1
ID,姓名,部门,yoj
1, 戈帕尔, TP, 2012
2、基兰,人力资源,2012
3、kaleel,SC, 2013
4、Prasanth, SC, 2013
上面的数据使用 year 分成两个文件。
/tab1/employeedata/2012/file2
1, 戈帕尔, TP, 2012
2、基兰,人力资源,2012
/tab1/employeedata/2013/file3
3、kaleel,SC, 2013
4、Prasanth, SC, 2013
添加分区
我们可以通过更改表来向表添加分区。假设我们有一个名为employee的表,其中包含Id、Name、Salary、Designation、Dept 和yoj 等字段。
句法:
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (p_column = p_col_value, p_column = p_col_value, ...)
以下查询用于向员工表添加分区。
hive> ALTER TABLE employee > ADD PARTITION (year=’2012’) > location '/2012/part2012';
重命名分区
该命令的语法如下。
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
以下查询用于重命名分区:
hive> ALTER TABLE employee PARTITION (year=’1203’) > RENAME TO PARTITION (Yoj=’1203’);
删除分区
以下语法用于删除分区:
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec, PARTITION partition_spec,...;
以下查询用于删除分区:
hive> ALTER TABLE employee DROP [IF EXISTS] > PARTITION (year=’1203’);
Hive – 内置运算符
本章解释了 Hive 的内置操作符。Hive 中有四种类型的运算符:
- 关系运算符
- 算术运算符
- 逻辑运算符
- 复杂运算符
关系运算符
这些运算符用于比较两个操作数。下表描述了 Hive 中可用的关系运算符:
| Operator | 操作数 | 描述 |
|---|---|---|
| A = B | 所有原始类型 | 如果表达式 A 等价于表达式 B,则为 TRUE,否则为 FALSE。 |
| A != B | 所有原始类型 | 如果表达式 A 不等于表达式 B,则为 TRUE,否则为 FALSE。 |
| A < B | 所有原始类型 | 如果表达式 A 小于表达式 B,则为 TRUE,否则为 FALSE。 |
| A <= B | 所有原始类型 | 如果表达式 A 小于或等于表达式 B,则为 TRUE,否则为 FALSE。 |
| A > B | 所有原始类型 | 如果表达式 A 大于表达式 B,则为 TRUE,否则为 FALSE。 |
| A >= B | 所有原始类型 | 如果表达式 A 大于或等于表达式 B,则为 TRUE,否则为 FALSE。 |
| A IS NULL | 所有类型 | 如果表达式 A 的计算结果为 NULL,则为 TRUE,否则为 FALSE。 |
| A IS NOT NULL | 所有类型 | 如果表达式 A 的计算结果为 NULL,则为 FALSE,否则为 TRUE。 |
| A LIKE B | 字符串 | 如果字符串模式 A 与 B 匹配,则为 TRUE,否则为 FALSE。 |
| A RLIKE B | 字符串 | 如果 A 或 B 为 NULL,则为 NULL,如果 A 的任何子字符串与 Java 正则表达式 B 匹配,则为 TRUE,否则为 FALSE。 |
| A REGEXP B | 字符串 | 与 RLIKE 相同。 |
例子
让我们假设员工表由名为 Id、Name、Salary、Designation 和 Dept 的字段组成,如下所示。生成查询以检索 ID 为 1205 的员工详细信息。
+-----+--------------+--------+---------------------------+------+ | Id | Name | Salary | Designation | Dept | +-----+--------------+------------------------------------+------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin| +-----+--------------+--------+---------------------------+------+
执行以下查询以使用上表检索员工详细信息:
hive> SELECT * FROM employee WHERE Id=1205;
成功执行查询后,您将看到以下响应:
+-----+-----------+-----------+----------------------------------+ | ID | Name | Salary | Designation | Dept | +-----+---------------+-------+----------------------------------+ |1205 | Kranthi | 30000 | Op Admin | Admin | +-----+-----------+-----------+----------------------------------+
执行以下查询以检索薪水大于或等于 40000 卢比的员工详细信息。
hive> SELECT * FROM employee WHERE Salary>=40000;
成功执行查询后,您将看到以下响应:
+-----+------------+--------+----------------------------+------+ | ID | Name | Salary | Designation | Dept | +-----+------------+--------+----------------------------+------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali| 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | +-----+------------+--------+----------------------------+------+
算术运算符
这些运算符支持对操作数进行各种常见的算术运算。它们都返回数字类型。下表描述了 Hive 中可用的算术运算符:
| Operators | 操作数 | 描述 |
|---|---|---|
| A + B | 所有数字类型 | 给出 A 和 B 相加的结果。 |
| A – B | 所有数字类型 | 给出从 A 中减去 B 的结果。 |
| A * B | 所有数字类型 | 给出 A 和 B 相乘的结果。 |
| A / B | 所有数字类型 | 给出 B 与 A 相除的结果。 |
| A % B | 所有数字类型 | 给出将 A 除以 B 的提示。 |
| A & B | 所有数字类型 | 给出 A 和 B 的按位 AND 结果。 |
| A | B | 所有数字类型 | 给出 A 和 B 的按位 OR 的结果。 |
| A ^ B | 所有数字类型 | 给出 A 和 B 的按位异或的结果。 |
| ~A | 所有数字类型 | 给出 A 的按位非结果。 |
例子
以下查询将两个数字相加,20 和 30。
hive> SELECT 20+30 ADD FROM temp;
成功执行查询后,您将看到以下响应:
+--------+ | ADD | +--------+ | 50 | +--------+
逻辑运算符
运算符是逻辑表达式。它们都返回 TRUE 或 FALSE。
| Operators | 操作数 | 描述 |
|---|---|---|
| A AND B | 布尔值 | 如果 A 和 B 都为 TRUE,则为 TRUE,否则为 FALSE。 |
| A && B | 布尔值 | 与 A AND B 相同。 |
| A OR B | 布尔值 | 如果 A 或 B 或两者都为 TRUE,则为 TRUE,否则为 FALSE。 |
| A || B | 布尔值 | 与 A 或 B 相同。 |
| NOT A | 布尔值 | 如果 A 为 FALSE,则为 TRUE,否则为 FALSE。 |
| !A | 布尔值 | 与 NOT A 相同。 |
例子
以下查询用于检索部门为 TP 且薪水超过 40000 卢比的员工详细信息。
hive> SELECT * FROM employee WHERE Salary>40000 && Dept=TP;
成功执行查询后,您将看到以下响应:
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | +------+--------------+-------------+-------------------+--------+
复杂运算符
这些运算符提供了访问复杂类型元素的表达式。
| Operator | 操作数 | 描述 |
|---|---|---|
| A[n] | A 是一个数组,n 是一个 int | 它返回数组 A 中的第 n 个元素。第一个元素的索引为 0。 |
| M[key] | M 是 Map<K, V> 并且键的类型为 K | 它返回与地图中的键对应的值。 |
| S.x | S 是一个结构体 | 它返回 S 的 x 字段。 |
Hiveql 选择…哪里
Hive 查询语言 (HiveQL) 是 Hive 用于处理和分析 Metastore 中结构化数据的查询语言。本章解释了如何使用带有 WHERE 子句的 SELECT 语句。
SELECT 语句用于从表中检索数据。WHERE 子句的工作方式类似于条件。它使用条件过滤数据并为您提供有限结果。内置运算符和函数生成满足条件的表达式。
句法
下面给出了 SELECT 查询的语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number];
例子
让我们以 SELECT…WHERE 子句为例。假设我们有如下所示的员工表,其中包含名为 Id、Name、Salary、Designation 和 Dept 的字段。生成一个查询以检索薪水超过 30000 卢比的员工详细信息。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查询使用上述场景检索员工详细信息:
hive> SELECT * FROM employee WHERE salary>30000;
成功执行查询后,您将看到以下响应:
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | +------+--------------+-------------+-------------------+--------+
JDBC程序
给定示例应用 where 子句的 JDBC 程序如下。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLWhere {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee WHERE
salary>30000;");
System.out.println("Result:");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
}
将程序保存在名为 HiveQLWhere.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveQLWhere.java $ java HiveQLWhere
输出:
ID Name Salary Designation Dept 1201 Gopal 45000 Technical manager TP 1202 Manisha 45000 Proofreader PR 1203 Masthanvali 40000 Technical writer TP 1204 Krian 40000 Hr Admin HR
Hiveql 选择…订购方式
本章说明如何在 SELECT 语句中使用 ORDER BY 子句。ORDER BY 子句用于根据一列检索详细信息,并按升序或降序对结果集进行排序。
句法
下面给出的是 ORDER BY 子句的语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list]] [LIMIT number];
例子
让我们以 SELECT…ORDER BY 子句为例。假设员工表如下所示,字段名为 Id、Name、Salary、Designation 和 Dept。生成查询以使用部门名称按顺序检索员工详细信息。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查询使用上述场景检索员工详细信息:
hive> SELECT Id, Name, Dept FROM employee ORDER BY DEPT;
成功执行查询后,您将看到以下响应:
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1205 | Kranthi | 30000 | Op Admin | Admin | |1204 | Krian | 40000 | Hr Admin | HR | |1202 | Manisha | 45000 | Proofreader | PR | |1201 | Gopal | 45000 | Technical manager | TP | |1203 | Masthanvali | 40000 | Technical writer | TP | +------+--------------+-------------+-------------------+--------+
JDBC程序
这是对给定示例应用 Order By 子句的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLOrderBy {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee ORDER BY
DEPT;");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
}
将程序保存在名为 HiveQLOrderBy.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveQLOrderBy.java $ java HiveQLOrderBy
输出:
ID Name Salary Designation Dept 1205 Kranthi 30000 Op Admin Admin 1204 Krian 40000 Hr Admin HR 1202 Manisha 45000 Proofreader PR 1201 Gopal 45000 Technical manager TP 1203 Masthanvali 40000 Technical writer TP 1204 Krian 40000 Hr Admin HR
Hiveql 分组依据
本章解释 SELECT 语句中 GROUP BY 子句的详细信息。GROUP BY 子句用于使用特定的集合列对结果集中的所有记录进行分组。它用于查询一组记录。
句法
GROUP BY 子句的语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list]] [LIMIT number];
例子
让我们以 SELECT…GROUP BY 子句为例。假设员工表如下所示,包含 Id、Name、Salary、Designation 和 Dept 字段。生成查询以检索每个部门的员工人数。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 45000 | Proofreader | PR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查询使用上述场景检索员工详细信息。
hive> SELECT Dept,count(*) FROM employee GROUP BY DEPT;
成功执行查询后,您将看到以下响应:
+------+--------------+ | Dept | Count(*) | +------+--------------+ |Admin | 1 | |PR | 2 | |TP | 3 | +------+--------------+
JDBC程序
下面给出的是为给定示例应用 Group By 子句的 JDBC 程序。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLGroupBy {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery(“SELECT Dept,count(*) ”
+“FROM employee GROUP BY DEPT; ”);
System.out.println(" Dept \t count(*)");
while (res.next()) {
System.out.println(res.getString(1)+" "+ res.getInt(2));
}
con.close();
}
}
将程序保存在名为 HiveQLGroupBy.java 的文件中。使用以下命令编译并执行该程序。
$ javac HiveQLGroupBy.java $ java HiveQLGroupBy
输出:
Dept Count(*) Admin 1 PR 2 TP 3
Hiveql 连接
JOINS 是一个子句,用于通过使用每个表的公共值来组合两个表中的特定字段。它用于组合来自数据库中两个或多个表的记录。
句法
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference
join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition]
例子
我们将在本章中使用以下两个表。考虑下表名为 CUSTOMERS..
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
考虑另一个表 ORDERS,如下所示:
+-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
有不同类型的连接,如下所示:
- 加入
- 左外连接
- 右外连接
- 全外连接
加入
JOIN 子句用于组合和检索多个表中的记录。JOIN 与 SQL 中的 OUTER JOIN 相同。将使用表的主键和外键引发 JOIN 条件。
以下查询在 CUSTOMER 和 ORDER 表上执行 JOIN,并检索记录:
hive> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT > FROM CUSTOMERS c JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,您将看到以下响应:
+----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
左外连接
即使右表中没有匹配项,HiveQL LEFT OUTER JOIN 也会返回左表中的所有行。这意味着,如果 ON 子句与右表中的 0(零)条记录匹配,则 JOIN 仍会在结果中返回一行,但右表中的每一列都为 NULL。
LEFT JOIN 返回左表中的所有值,加上右表中匹配的值,如果没有匹配的 JOIN 谓词,则返回 NULL。
以下查询演示了 CUSTOMER 和 ORDER 表之间的 LEFT OUTER JOIN:
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > LEFT OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,您将看到以下响应:
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | +----+----------+--------+---------------------+
右外连接
即使左表中没有匹配项,HiveQL RIGHT OUTER JOIN 也会返回右表中的所有行。如果 ON 子句与左表中的 0(零)条记录匹配,则 JOIN 仍会在结果中返回一行,但左表中的每一列都为 NULL。
RIGHT JOIN 返回右表中的所有值,加上左表中匹配的值,如果没有匹配的连接谓词,则返回 NULL。
以下查询演示了 CUSTOMER 和 ORDER 表之间的 RIGHT OUTER JOIN。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > RIGHT OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,您将看到以下响应:
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
全外连接
HiveQL FULL OUTER JOIN 组合了满足 JOIN 条件的左右外部表的记录。连接表包含两个表中的所有记录,或者为任一侧丢失的匹配项填充 NULL 值。
以下查询演示了 CUSTOMER 和 ORDER 表之间的 FULL OUTER JOIN:
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > FULL OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,您将看到以下响应:
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
Hive – 内置函数
本章介绍 Hive 中可用的内置函数。这些函数看起来与 SQL 函数非常相似,只是它们的用法不同。
内置函数
Hive 支持以下内置函数:
| Return Type | 签名 | 描述 |
|---|---|---|
| BIGINT | 圆形(双A) | 它返回双精度值的舍入 BIGINT 值。 |
| BIGINT | 地板(双A) | 它返回等于或小于双精度值的最大 BIGINT 值。 |
| BIGINT | 细胞(双A) | 它返回等于或大于双精度值的最小 BIGINT 值。 |
| double | rand(), rand(int 种子) | 它返回一个随行变化的随机数。 |
| string | concat(字符串A,字符串B,…) | 它返回在 A 之后连接 B 产生的字符串。 |
| string | substr(string A, int start) | 它返回 A 的子串从起始位置开始到字符串 A 的结尾。 |
| string | substr(string A, int start, int length) | 它以给定的长度返回从起始位置开始的 A 的子字符串。 |
| string | 上(字符串 A) | 它返回将 A 的所有字符转换为大写的字符串。 |
| string | ucase(string A) | Same as above. |
| 细绳 | 下(字符串 A) | 它返回将 B 的所有字符转换为小写的字符串。 |
| string | lcase(字符串A) | 和上面一样。 |
| string | 修剪(字符串A) | 它返回从 A 的两端修剪空格产生的字符串。 |
| string | ltrim(字符串 A) | 它返回从 A 的开头(左侧)修剪空格产生的字符串。 |
| string | rtrim(字符串A) | rtrim(string A) 它返回从 A 的末尾(右侧)修剪空格产生的字符串。 |
| string | regexp_replace(字符串A,字符串B,字符串C) | 它返回通过用 C 替换 B 中与 Java 正则表达式语法匹配的所有子字符串而产生的字符串。 |
| int | 大小(地图<KV>) | 它返回地图类型中元素的数量。 |
| int | 大小(数组<T>) | 它返回数组类型中的元素数。 |
| value of <type> | cast(<expr> as <type>) | 它将表达式 expr 的结果转换为 <type> 例如 cast(‘1’ as BIGINT) 将字符串 ‘1’ 转换为其整数表示。如果转换不成功,则返回 NULL。 |
| string | from_unixtime(int unixtime) | 将 Unix 纪元 (1970-01-01 00:00:00 UTC) 的秒数转换为表示当前系统时区中该时刻时间戳的字符串,格式为“1970-01-01 00:00: 00″ |
| string | to_date(字符串时间戳) | 它返回时间戳字符串的日期部分: to_date(“1970-01-01 00:00:00”) = “1970-01-01” |
| int | 年(字符串日期) | 它返回日期或时间戳字符串的年份部分: year(“1970-01-01 00:00:00”) = 1970, year(“1970-01-01”) = 1970 |
| int | 月份(字符串日期) | 它返回日期的月份部分或时间戳字符串:month(“1970-11-01 00:00:00”) = 11, month(“1970-11-01”) = 11 |
| int | 天(字符串日期) | 它返回日期或时间戳字符串的日期部分:day(“1970-11-01 00:00:00”) = 1, day(“1970-11-01”) = 1 |
| string | get_json_object(string json_string, string path) | 它根据指定的 json 路径从 json 字符串中提取 json 对象,并返回提取的 json 对象的 json 字符串。如果输入的 json 字符串无效,则返回 NULL。 |
例子
以下查询演示了一些内置函数:
round() 函数
hive> SELECT round(2.6) from temp;
成功执行查询后,您将看到以下响应:
3.0
floor() 函数
hive> SELECT floor(2.6) from temp;
成功执行查询后,您将看到以下响应:
2.0
细胞()函数
hive> SELECT ceil(2.6) from temp;
成功执行查询后,您将看到以下响应:
3.0
聚合函数
Hive 支持以下内置聚合函数。这些函数的用法与 SQL 聚合函数相同。
| Return Type | 签名 | 描述 |
|---|---|---|
| BIGINT | 计数(*),计数(表达式), | count(*) – 返回检索到的总行数。 |
| DOUBLE | sum(col), sum(DISTINCT col) | 它返回组中元素的总和或组中列的不同值的总和。 |
| DOUBLE | avg(col), avg(DISTINCT col) | 它返回组中元素的平均值或组中列的不同值的平均值。 |
| DOUBLE | 分钟(列) | 它返回组中列的最小值。 |
| DOUBLE | 最大值(列) | 它返回组中列的最大值。 |
Hive – 视图和索引
本章介绍如何创建和管理视图。视图是根据用户需求生成的。您可以将任何结果集数据保存为视图。Hive 中视图的用法与 SQL 中视图的用法相同。这是一个标准的 RDBMS 概念。我们可以在一个视图上执行所有 DML 操作。
创建视图
您可以在执行 SELECT 语句时创建视图。语法如下:
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT table_comment] AS SELECT ...
例子
让我们举个例子来看看。假设员工表如下所示,包含字段 Id、Name、Salary、Designation 和 Dept。生成一个查询以检索工资超过 30000 卢比的员工详细信息。我们将结果存储在名为emp_30000的视图中。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查询使用上述场景检索员工详细信息:
hive> CREATE VIEW emp_30000 AS > SELECT * FROM employee > WHERE salary>30000;
删除视图
使用以下语法删除视图:
DROP VIEW view_name
以下查询删除名为 emp_30000 的视图:
hive> DROP VIEW emp_30000;
创建索引
索引只不过是表特定列上的指针。创建索引意味着在表的特定列上创建一个指针。其语法如下:
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS 'index.handler.class.name' [WITH DEFERRED REBUILD] [IDXPROPERTIES (property_name=property_value, ...)] [IN TABLE index_table_name] [PARTITIONED BY (col_name, ...)] [ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION hdfs_path] [TBLPROPERTIES (...)]
例子
让我们以索引为例。使用我们之前使用过的带有字段 Id、Name、Salary、Designation 和 Dept 的员工表。在员工表的薪水列上创建一个名为 index_salary 的索引。
以下查询创建索引:
hive> CREATE INDEX inedx_salary ON TABLE employee(salary) > AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';
它是一个指向工资列的指针。如果修改了列,则使用索引值存储更改。
删除索引
以下语法用于删除索引:
DROP INDEX <index_name> ON <table_name>
以下查询删除名为 index_salary 的索引:
hive> DROP INDEX index_salary ON employee;
