Kubernetes – 快速指南
Kubernetes – 快速指南
Kubernetes – 概述
Kubernetes 在由云原生计算基金会 (CNCF) 托管的开源容器管理工具中。这也被称为 Borg 的增强版本,它是由 Google 开发的,用于管理长时间运行的进程和批处理作业,这些作业早先由单独的系统处理。
Kubernetes 具有跨集群自动化部署、应用程序扩展和应用程序容器操作的能力。它能够创建以容器为中心的基础设施。
Kubernetes 的特点
以下是 Kubernetes 的一些重要特性。
-
持续开发、集成和部署
-
容器化基础设施
-
以应用为中心的管理
-
可自动扩展的基础架构
-
开发测试和生产的环境一致性
-
松散耦合的基础设施,其中每个组件都可以作为一个单独的单元
-
更高的资源利用密度
-
将要创建的可预测的基础设施
Kubernetes 的关键组件之一是,它可以在物理和虚拟机基础架构的集群上运行应用程序。它还具有在云上运行应用程序的能力。它有助于从以主机为中心的基础设施转变为以容器为中心的基础设施。
Kubernetes – 架构
在本章中,我们将讨论 Kubernetes 的基本架构。
Kubernetes – 集群架构
如下图所示,Kubernetes 遵循客户端-服务器架构。其中,我们在一台机器上安装了master,在不同的Linux机器上安装了node。
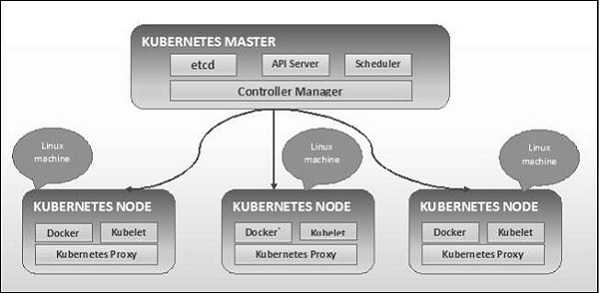
master 和 node 的关键组件在下一节中定义。
Kubernetes – 主机组件
以下是 Kubernetes Master Machine 的组件。
等
它存储集群中每个节点都可以使用的配置信息。它是一个高可用的键值存储,可以分布在多个节点之间。它只能由 Kubernetes API 服务器访问,因为它可能包含一些敏感信息。它是一个所有人都可以访问的分布式键值存储。
接口服务器
Kubernetes 是一个 API 服务器,它使用 API 提供集群上的所有操作。API 服务器实现了一个接口,这意味着不同的工具和库可以很容易地与之通信。Kubeconfig是一个包以及可用于通信的服务器端工具。它公开了 Kubernetes API。
控制器管理器
该组件负责调节集群状态和执行任务的大部分收集器。一般来说,它可以被认为是一个运行在非终止循环中的守护进程,负责收集信息并将其发送到 API 服务器。它致力于获取集群的共享状态,然后进行更改以使服务器的当前状态达到所需状态。关键控制器是复制控制器、端点控制器、命名空间控制器和服务帐户控制器。控制器管理器运行不同类型的控制器来处理节点、端点等。
调度器
这是 Kubernetes master 的关键组件之一。它是 master 中的一项服务,负责分配工作负载。它负责跟踪集群节点上工作负载的利用率,然后将可用资源放置在工作负载上并接受工作负载。换句话说,这是负责将 pod 分配给可用节点的机制。调度器负责工作负载利用率并将 pod 分配给新节点。
Kubernetes – 节点组件
以下是与 Kubernetes master 通信所必需的 Node 服务器的关键组件。
码头工人
每个节点的第一个需求是 Docker,它有助于在相对隔离但轻量级的操作环境中运行封装的应用程序容器。
Kubelet 服务
这是每个节点中的一个小服务,负责将信息中继到控制平面服务和从控制平面服务中继信息。它与etcd存储交互以读取配置详细信息和 wright 值。这与主组件通信以接收命令和工作。然后kubelet进程负责维护工作状态和节点服务器。它管理网络规则、端口转发等。
Kubernetes 代理服务
这是在每个节点上运行的代理服务,有助于使服务可用于外部主机。它有助于将请求转发到正确的容器,并能够执行原始负载平衡。它确保网络环境是可预测和可访问的,同时它也是隔离的。它管理节点上的 pod、卷、秘密、创建新容器的健康检查等。
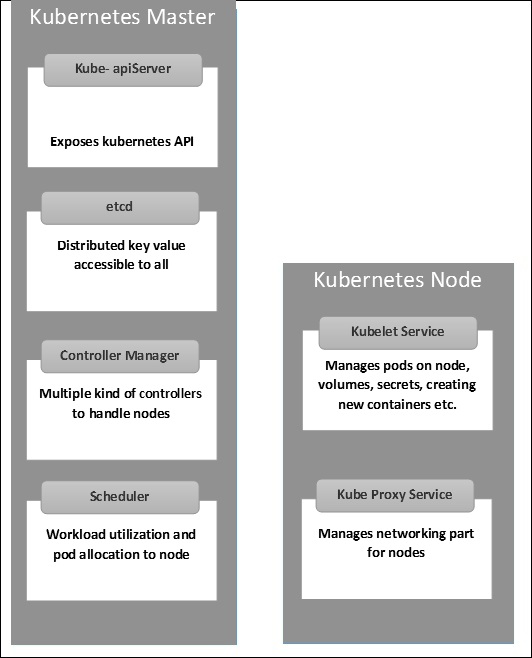
Kubernetes – 主节点结构
下图显示了 Kubernetes Master 和 Node.js 的结构。
Kubernetes – 设置
在设置 Kubernetes 之前设置虚拟数据中心 (vDC) 很重要。这可以被视为一组机器,它们可以通过网络相互通信。对于动手操作的方法,如果您没有设置物理或云基础架构,您可以在PROFITBRICKS上设置 vDC 。
在任何云上的 IaaS 设置完成后,您需要配置Master和Node。
注意– 显示了 Ubuntu 机器的设置。同样的设置也可以在其他 Linux 机器上进行。
先决条件
安装 Docker – 所有 Kubernetes 实例都需要 Docker。以下是安装 Docker 的步骤。
步骤 1 – 使用 root 用户帐户登录机器。
步骤 2 – 更新包信息。确保 apt 包正在运行。
步骤 3 – 运行以下命令。
$ sudo apt-get update $ sudo apt-get install apt-transport-https ca-certificates
步骤 4 – 添加新的 GPG 密钥。
$ sudo apt-key adv \ --keyserver hkp://ha.pool.sks-keyservers.net:80 \ --recv-keys 58118E89F3A912897C070ADBF76221572C52609D $ echo "deb https://apt.dockerproject.org/repo ubuntu-trusty main" | sudo tee /etc/apt/sources.list.d/docker.list
步骤 5 – 更新 API 包映像。
$ sudo apt-get update
完成上述所有任务后,您就可以开始实际安装 Docker 引擎了。但是,在此之前您需要验证您使用的内核版本是否正确。
安装 Docker 引擎
运行以下命令安装 Docker 引擎。
步骤 1 – 登录机器。
步骤 2 – 更新包索引。
$ sudo apt-get update
步骤 3 – 使用以下命令安装 Docker 引擎。
$ sudo apt-get install docker-engine
第 4 步– 启动 Docker 守护进程。
$ sudo apt-get install docker-engine
第 5 步– 如果安装了 Docker,请使用以下命令。
$ sudo docker run hello-world
安装 etcd 2.0
这需要安装在 Kubernetes Master Machine 上。要安装它,请运行以下命令。
$ curl -L https://github.com/coreos/etcd/releases/download/v2.0.0/etcd -v2.0.0-linux-amd64.tar.gz -o etcd-v2.0.0-linux-amd64.tar.gz ->1 $ tar xzvf etcd-v2.0.0-linux-amd64.tar.gz ------>2 $ cd etcd-v2.0.0-linux-amd64 ------------>3 $ mkdir /opt/bin ------------->4 $ cp etcd* /opt/bin ----------->5
在上面的命令集中 –
- 首先,我们下载etcd。用指定的名称保存它。
- 然后,我们必须解压缩 tar 包。
- 我们做一个目录。在 /opt 命名的 bin 中。
- 将提取的文件复制到目标位置。
现在我们已准备好构建 Kubernetes。我们需要在集群上的所有机器上安装 Kubernetes。
$ git clone https://github.com/GoogleCloudPlatform/kubernetes.git $ cd kubernetes $ make release
上面的命令将在 kubernetes 文件夹的根目录中创建一个_output目录。接下来,我们可以将该目录解压缩到我们选择的任何目录 /opt/bin 等中。
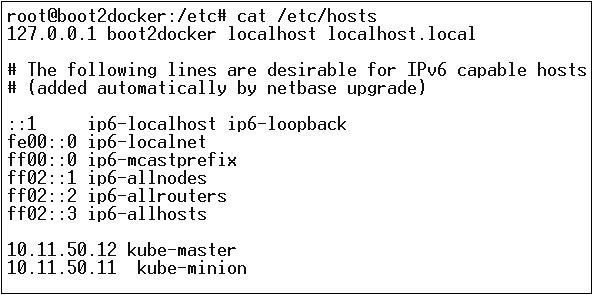
接下来是网络部分,我们需要真正开始设置 Kubernetes 主节点和节点。为此,我们将在主机文件中创建一个条目,该条目可以在节点机器上完成。
$ echo "<IP address of master machine> kube-master < IP address of Node Machine>" >> /etc/hosts
以下将是上述命令的输出。
现在,我们将从 Kubernetes Master 上的实际配置开始。
首先,我们将开始将所有配置文件复制到正确的位置。
$ cp <Current dir. location>/kube-apiserver /opt/bin/ $ cp <Current dir. location>/kube-controller-manager /opt/bin/ $ cp <Current dir. location>/kube-kube-scheduler /opt/bin/ $ cp <Current dir. location>/kubecfg /opt/bin/ $ cp <Current dir. location>/kubectl /opt/bin/ $ cp <Current dir. location>/kubernetes /opt/bin/
上述命令会将所有配置文件复制到所需位置。现在我们将回到我们构建 Kubernetes 文件夹的同一目录。
$ cp kubernetes/cluster/ubuntu/init_conf/kube-apiserver.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-controller-manager.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-kube-scheduler.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-apiserver /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-controller-manager /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-kube-scheduler /etc/init.d/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/
下一步是更新/etc下复制的配置文件。目录
使用以下命令在 master 上配置 etcd。
$ ETCD_OPTS = "-listen-client-urls = http://kube-master:4001"
配置 kube-apiserver
为此,我们需要编辑我们之前复制的/etc/default/kube-apiserver文件。
$ KUBE_APISERVER_OPTS = "--address = 0.0.0.0 \ --port = 8080 \ --etcd_servers = <The path that is configured in ETCD_OPTS> \ --portal_net = 11.1.1.0/24 \ --allow_privileged = false \ --kubelet_port = < Port you want to configure> \ --v = 0"
配置 kube 控制器管理器
我们需要在/etc/default/kube-controller-manager 中添加以下内容。
$ KUBE_CONTROLLER_MANAGER_OPTS = "--address = 0.0.0.0 \ --master = 127.0.0.1:8080 \ --machines = kube-minion \ -----> #this is the kubernatics node --v = 0
接下来在对应的文件中配置kube调度器。
$ KUBE_SCHEDULER_OPTS = "--address = 0.0.0.0 \ --master = 127.0.0.1:8080 \ --v = 0"
完成上述所有任务后,我们就可以启动 Kubernetes Master。为此,我们将重新启动 Docker。
$ service docker restart
Kubernetes 节点配置
Kubernetes 节点将运行两个服务kubelet 和 kube-proxy。在继续之前,我们需要将下载的二进制文件复制到我们想要配置 kubernetes 节点的所需文件夹中。
使用与我们为 kubernetes master 所做的相同的方法复制文件。因为它只会运行 kubelet 和 kube-proxy,我们将配置它们。
$ cp <Path of the extracted file>/kubelet /opt/bin/ $ cp <Path of the extracted file>/kube-proxy /opt/bin/ $ cp <Path of the extracted file>/kubecfg /opt/bin/ $ cp <Path of the extracted file>/kubectl /opt/bin/ $ cp <Path of the extracted file>/kubernetes /opt/bin/
现在,我们将内容复制到适当的目录。
$ cp kubernetes/cluster/ubuntu/init_conf/kubelet.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-proxy.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kubelet /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-proxy /etc/init.d/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/
我们将配置kubelet和kube-proxy conf文件。
我们将配置/etc/init/kubelet.conf。
$ KUBELET_OPTS = "--address = 0.0.0.0 \ --port = 10250 \ --hostname_override = kube-minion \ --etcd_servers = http://kube-master:4001 \ --enable_server = true --v = 0" /
对于 kube-proxy,我们将使用以下命令进行配置。
$ KUBE_PROXY_OPTS = "--etcd_servers = http://kube-master:4001 \ --v = 0" /etc/init/kube-proxy.conf
最后,我们将重新启动 Docker 服务。
$ service docker restart
现在我们完成了配置。您可以通过运行以下命令进行检查。
$ /opt/bin/kubectl get minions
Kubernetes – 图像
Kubernetes (Docker) 镜像是容器化基础设施的关键构建块。截至目前,我们仅支持 Kubernetes 以支持 Docker 镜像。Pod 中的每个容器都有其 Docker 映像在其中运行。
当我们配置 Pod 时,配置文件中的 image 属性与 Docker 命令的语法相同。配置文件有一个字段来定义映像名称,我们计划从注册表中提取该名称。
以下是从 Docker 注册表中拉取镜像并部署到 Kubernetes 容器的通用配置结构。
apiVersion: v1
kind: pod
metadata:
name: Tesing_for_Image_pull -----------> 1
spec:
containers:
- name: neo4j-server ------------------------> 2
image: <Name of the Docker image>----------> 3
imagePullPolicy: Always ------------->4
command: ["echo", "SUCCESS"] ------------------->
在上面的代码中,我们定义了 –
-
name: Tesing_for_Image_pull – 此名称用于识别和检查从 Docker 注册表中提取图像后将创建的容器的名称。
-
name: neo4j-server – 这是我们尝试创建的容器的名称。就像我们给了neo4j-server一样。
-
image: <Name of the Docker image> – 这是我们试图从 Docker 或内部镜像注册表中提取的镜像的名称。我们需要定义一个完整的注册表路径以及我们尝试提取的映像名称。
-
imagePullPolicy – 始终 – 此图像拉取策略定义每当我们运行此文件以创建容器时,它将再次拉取相同的名称。
-
命令:[“echo”,“SUCCESS”] – 这样,当我们创建容器时,如果一切正常,它将在我们访问容器时显示一条消息。
为了拉取镜像并创建容器,我们将运行以下命令。
$ kubectl create –f Tesing_for_Image_pull
获取日志后,我们将获得成功的输出。
$ kubectl log Tesing_for_Image_pull
上面的命令将产生一个成功的输出,或者我们将得到一个失败的输出。
注意– 建议您自己尝试所有命令。
Kubernetes – 工作
作业的主要功能是创建一个或多个 Pod 并跟踪 Pod 的成功。它们确保指定数量的 Pod 成功完成。当指定数量的 pod 成功运行完成时,则认为该作业已完成。
创建工作
使用以下命令创建作业 –
apiVersion: v1
kind: Job ------------------------> 1
metadata:
name: py
spec:
template:
metadata
name: py -------> 2
spec:
containers:
- name: py ------------------------> 3
image: python----------> 4
command: ["python", "SUCCESS"]
restartPocliy: Never --------> 5
在上面的代码中,我们定义了 –
-
kind: Job →我们已经将 kind 定义为 Job,它会告诉kubectl正在使用的yaml文件是创建一个作业类型 pod。
-
Name:py →这是我们正在使用的模板的名称,规范定义了模板。
-
name: py →我们在容器规范下命名为py,这有助于识别将要从中创建的 Pod。
-
图像:python →我们要拉取的图像来创建将在 pod 内运行的容器。
-
restartPolicy: Never →这个镜像重启的条件是从不给出的,这意味着如果容器被杀死或者它是假的,那么它不会重启自己。
我们将使用以下命令使用 yaml 创建作业,该 yaml 以名称py.yaml保存。
$ kubectl create –f py.yaml
上面的命令将创建一个作业。如果要检查作业的状态,请使用以下命令。
$ kubectl describe jobs/py
上面的命令将创建一个作业。如果要检查作业的状态,请使用以下命令。
预定作业
Kubernetes 中的计划作业使用Cronetes,它获取 Kubernetes 作业并在 Kubernetes 集群中启动它们。
- 调度作业将在指定的时间点运行 pod。
- 为它创建了一个模仿作业,它会自动调用自己。
注意– 1.4 版支持计划作业的功能,并且通过在启动 API 服务器时传递–runtime-config=batch/v2alpha1来打开 beetch/v2alpha 1 API 。
我们将使用与创建作业相同的 yaml 并将其设为预定作业。
apiVersion: v1
kind: Job
metadata:
name: py
spec:
schedule: h/30 * * * * ? -------------------> 1
template:
metadata
name: py
spec:
containers:
- name: py
image: python
args:
/bin/sh -------> 2
-c
ps –eaf ------------> 3
restartPocliy: OnFailure
在上面的代码中,我们定义了 –
-
时间表:h/30 * * * * ? → 安排作业每 30 分钟运行一次。
-
/bin/sh:这将与/bin/sh一起进入容器
-
ps –eaf →将在机器上运行 ps -eaf 命令并列出容器内所有正在运行的进程。
当我们尝试在指定的时间点构建和运行一组任务然后完成该过程时,此计划作业概念非常有用。
Kubernetes – 标签和选择器
标签
标签是附加到 pod、复制控制器和服务的键值对。它们用作对象(例如 pod 和复制控制器)的标识属性。它们可以在创建时添加到对象,也可以在运行时添加或修改。
选择器
标签不提供唯一性。一般来说,我们可以说许多对象可以带有相同的标签。标签选择器是 Kubernetes 中的核心分组原语。用户使用它们来选择一组对象。
Kubernetes API 目前支持两种类型的选择器 –
- 基于相等的选择器
- 基于集合的选择器
基于相等的选择器
它们允许按键和值进行过滤。匹配对象应满足所有指定的标签。
基于集合的选择器
基于集合的选择器允许根据一组值过滤键。
apiVersion: v1
kind: Service
metadata:
name: sp-neo4j-standalone
spec:
ports:
- port: 7474
name: neo4j
type: NodePort
selector:
app: salesplatform ---------> 1
component: neo4j -----------> 2
在上面的代码中,我们使用标签选择器作为app: salesplatform和组件作为组件:neo4j。
一旦我们使用kubectl命令运行该文件,它将创建一个名为sp-neo4j-standalone的服务,该服务将在端口 7474 上进行通信。 ype 是NodePort,新标签选择器为app: salesplatform和组件:neo4j。
Kubernetes – 命名空间
命名空间为资源名称提供了额外的限定。当多个团队使用同一个集群并且存在名称冲突的可能性时,这很有用。它可以作为多个集群之间的虚拟墙。
命名空间的功能
以下是 Kubernetes 中命名空间的一些重要功能 –
-
命名空间有助于使用相同命名空间的 pod 到 pod 通信。
-
命名空间是可以位于同一个物理集群之上的虚拟集群。
-
它们在团队和他们的环境之间提供了逻辑分离。
创建命名空间
以下命令用于创建命名空间。
apiVersion: v1 kind: Namespce metadata name: elk
控制命名空间
以下命令用于控制命名空间。
$ kubectl create –f namespace.yml ---------> 1 $ kubectl get namespace -----------------> 2 $ kubectl get namespace <Namespace name> ------->3 $ kubectl describe namespace <Namespace name> ---->4 $ kubectl delete namespace <Namespace name>
在上面的代码中,
- 我们正在使用该命令来创建命名空间。
- 这将列出所有可用的命名空间。
- 这将获得一个特定的命名空间,其名称在命令中指定。
- 这将描述有关该服务的完整详细信息。
- 这将删除集群中存在的特定命名空间。
在服务中使用命名空间 – 示例
以下是在服务中使用命名空间的示例文件示例。
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCP
在上面的代码中,我们在名为elk 的服务元数据下使用了相同的命名空间。
Kubernetes – 节点
节点是 Kubernetes 集群中的一台工作机器,也称为 minion。它们是工作单元,可以是物理、VM 或云实例。
每个节点都有在其上运行 Pod 所需的所有配置,例如代理服务和 kubelet 服务以及 Docker,用于在节点上创建的 Pod 上运行 Docker 容器。
它们不是由 Kubernetes 创建的,而是由云服务提供商或物理或 VM 机器上的 Kubernetes 集群管理器在外部创建的。
Kubernetes 处理多个节点的关键组件是控制器管理器,它运行多种控制器来管理节点。为了管理节点,Kubernetes 创建了一个节点类型的对象,它将验证创建的对象是一个有效的节点。
带选择器的服务
apiVersion: v1
kind: node
metadata:
name: < ip address of the node>
labels:
name: <lable name>
以 JSON 格式创建实际对象,如下所示 –
{
Kind: node
apiVersion: v1
"metadata":
{
"name": "10.01.1.10",
"labels"
{
"name": "cluster 1 node"
}
}
}
节点控制器
它们是在 Kubernetes master 中运行并根据 metadata.name 持续监控集群中节点的服务的集合。如果所有必需的服务都在运行,则验证该节点,并且控制器将新创建的 pod 分配给该节点。如果它无效,那么 master 将不会为其分配任何 pod,并将等待它变为有效。
如果–register-node标志为真,Kubernetes 主节点会自动注册节点。
–register-node = true
但是,如果集群管理员想要手动管理它,那么可以通过转动平面来完成 –
–register-node = false
Kubernetes – 服务
服务可以定义为一组逻辑 pod。它可以被定义为 Pod 顶部的抽象,它提供一个单一的 IP 地址和 DNS 名称,通过它可以访问 Pod。使用 Service,可以非常轻松地管理负载平衡配置。它可以帮助 Pod 非常轻松地扩展。
服务是 Kubernetes 中的 REST 对象,其定义可以发布到 Kubernetes master 上的 Kubernetes apiServer 以创建新实例。
没有选择器的服务
apiVersion: v1 kind: Service metadata: name: Tutorial_point_service spec: ports: - port: 8080 targetPort: 31999
上述配置将创建一个名为 Tutorial_point_service 的服务。
带有选择器的服务配置文件
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: "My Application" -------------------> (Selector)
ports:
- port: 8080
targetPort: 31999
在这个例子中,我们有一个选择器;所以为了传输流量,我们需要手动创建一个端点。
apiVersion: v1
kind: Endpoints
metadata:
name: Tutorial_point_service
subnets:
address:
"ip": "192.168.168.40" -------------------> (Selector)
ports:
- port: 8080
在上面的代码中,我们创建了一个端点,它将流量路由到定义为“192.168.168.40:8080”的端点。
多端口服务创建
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: “My Application” -------------------> (Selector)
ClusterIP: 10.3.0.12
ports:
-name: http
protocol: TCP
port: 80
targetPort: 31999
-name:https
Protocol: TCP
Port: 443
targetPort: 31998
服务类型
ClusterIP – 这有助于限制集群内的服务。它在定义的 Kubernetes 集群中公开服务。
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: NodeportService
NodePort – 它将在已部署节点的静态端口上公开服务。NodePort服务将路由到的ClusterIP服务会自动创建。可以使用NodeIP:nodePort从集群外部访问该服务。
spec:
ports:
- port: 8080
nodePort: 31999
name: NodeportService
clusterIP: 10.20.30.40
负载均衡器– 它使用云提供商的负载均衡器。NodePort和ClusterIP服务是自动创建的,外部负载均衡器将路由到这些服务。
服务类型为节点端口的完整服务yaml文件。尝试自己创建一个。
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: env_name
Kubernetes – Pod
Pod 是容器及其存储在 Kubernetes 集群节点内的集合。可以创建一个包含多个容器的 pod。例如,将数据库容器和数据容器保存在同一个 Pod 中。
Pod 的类型
有两种类型的 Pod –
- 单容器吊舱
- 多容器吊舱
单个容器 Pod
它们可以简单地使用 kubctl run 命令创建,其中您在 Docker 注册表上有一个定义的镜像,我们将在创建 pod 时提取该镜像。
$ kubectl run <name of pod> --image=<name of the image from registry>
示例– 我们将使用 Docker 集线器上可用的 tomcat 映像创建一个 pod。
$ kubectl run tomcat --image = tomcat:8.0
这也可以通过创建yaml文件然后运行kubectl create命令来完成。
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: Always
上面的yaml文件创建完成后,我们将文件名保存为tomcat.yml并运行 create 命令来运行该文件。
$ kubectl create –f tomcat.yml
它将创建一个名为 tomcat 的 pod。我们可以使用 describe 命令和kubectl来描述 pod。
多容器吊舱
多容器 pod 是使用yaml mail和容器定义创建的。
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: Always
-name: Database
Image: mongoDB
Ports:
containerPort: 7501
imagePullPolicy: Always
在上面的代码中,我们创建了一个 pod,里面有两个容器,一个用于 tomcat,另一个用于 MongoDB。
Kubernetes – 复制控制器
Replication Controller 是 Kubernetes 的关键特性之一,它负责管理 pod 生命周期。它负责确保指定数量的 pod 副本在任何时间点都在运行。当需要确保指定数量的 pod 或至少一个 pod 正在运行时使用。它具有启动或关闭指定数量的 pod 的能力。
最好的做法是使用复制控制器来管理 pod 生命周期,而不是一次又一次地创建 pod。
apiVersion: v1
kind: ReplicationController --------------------------> 1
metadata:
name: Tomcat-ReplicationController --------------------------> 2
spec:
replicas: 3 ------------------------> 3
template:
metadata:
name: Tomcat-ReplicationController
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat- -----------------------> 4
image: tomcat: 8.0
ports:
- containerPort: 7474 ------------------------> 5
设置详情
-
种类:ReplicationController →在上面的代码中,我们定义了一种为复制控制器,它告诉kubectl的YAML文件将被用于创建复制控制器。
-
名称:Tomcat-ReplicationController → 这有助于识别将创建复制控制器的名称。如果我们运行 kubctl,获取rc < Tomcat-ReplicationController >它将显示复制控制器的详细信息。
-
replicas: 3 → 这有助于复制控制器了解它需要在 Pod 生命周期的任何时间点维护 Pod 的三个副本。
-
名称:Tomcat → 在规范部分,我们将名称定义为 tomcat,它将告诉复制控制器 pod 中存在的容器是 tomcat。
-
containerPort: 7474 → 它有助于确保 pod 运行 pod 内容器的集群中的所有节点都将暴露在同一个端口 7474 上。

在这里,Kubernetes 服务用作三个 tomcat 副本的负载均衡器。
Kubernetes – 副本集
副本集确保应该运行多少个 pod 副本。它可以被视为复制控制器的替代品。副本集和复制控制器的主要区别在于,复制控制器仅支持基于相等的选择器,而副本集支持基于集合的选择器。
apiVersion: extensions/v1beta1 --------------------->1
kind: ReplicaSet --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
selector:
matchLables:
tier: Backend ------------------> 3
matchExpression:
{ key: tier, operation: In, values: [Backend]} --------------> 4
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
- containerPort: 7474
设置详情
-
apiVersion: extensions/v1beta1 → 在上面的代码中,API 版本是 Kubernetes 的高级测试版,支持副本集的概念。
-
kind: ReplicaSet → 我们将 kind 定义为副本集,这有助于 kubectl 理解该文件用于创建副本集。
-
层:后端→ 我们已经将标签层定义为后端,它创建了一个匹配的选择器。
-
{key: tier, operation: In, values: [Backend]} → 这将有助于matchExpression了解我们定义的匹配条件以及matchlabel用于查找详细信息的操作。
使用kubectl运行上述文件并使用yaml文件中提供的定义创建后端副本集。

Kubernetes – 部署
部署升级和更高版本的复制控制器。他们管理副本集的部署,这也是复制控制器的升级版本。它们具有更新副本集的能力,也能够回滚到以前的版本。
它们提供了许多matchLabels和selectors 的更新功能。我们在 Kubernetes master 中有一个新的控制器,称为部署控制器,它实现了。它具有中途更改部署的能力。
更改部署
更新– 用户可以在完成之前更新正在进行的部署。在这种情况下,将解决现有部署并创建新部署。
删除– 用户可以通过在完成之前将其删除来暂停/取消部署。重新创建相同的部署将恢复它。
回滚– 我们可以回滚部署或正在进行的部署。用户可以使用DeploymentSpec.PodTemplateSpec = oldRC.PodTemplateSpec创建或更新部署。
部署策略
部署策略有助于定义新 RC 应如何替换现有 RC。
重新创建– 此功能将杀死所有现有的 RC,然后调出新的。这会导致快速部署,但是当旧 Pod 关闭而新 Pod 没有出现时,它会导致停机。
滚动更新– 此功能会逐渐降低旧的 RC 并启动新的 RC。这会导致部署缓慢,但没有部署。在任何时候,在此过程中都很少有旧 Pod 和新 Pod 可用。
Deployment 的配置文件是这样的。
apiVersion: extensions/v1beta1 --------------------->1
kind: Deployment --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
spec:
containers:
- name: Tomcatimage:
tomcat: 8.0
ports:
- containerPort: 7474
在上面的代码中,唯一与副本集不同的是我们将种类定义为部署。
创建部署
$ kubectl create –f Deployment.yaml -–record deployment "Deployment" created Successfully.
获取部署
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVILABLE AGE Deployment 3 3 3 3 20s
检查部署状态
$ kubectl rollout status deployment/Deployment
更新部署
$ kubectl set image deployment/Deployment tomcat=tomcat:6.0
回滚到之前的部署
$ kubectl rollout undo deployment/Deployment –to-revision=2
Kubernetes – 卷
在 Kubernetes 中,卷可以被认为是 pod 中的容器可以访问的目录。我们在 Kubernetes 中有不同类型的卷,类型定义了卷的创建方式及其内容。
Docker 中存在卷的概念,但唯一的问题是卷非常受限于特定的 pod。Pod 的生命周期一结束,音量也随之丢失。
另一方面,通过 Kubernetes 创建的卷不限于任何容器。它支持部署在 Kubernetes 的 pod 内的任何或所有容器。Kubernetes 卷的一个关键优势是,它支持不同类型的存储,其中 pod 可以同时使用多个存储。
Kubernetes 卷的类型
以下是一些流行的 Kubernetes Volumes 列表 –
-
emptyDir – 它是一种在 Pod 首次分配给节点时创建的卷。只要 Pod 在该节点上运行,它就会保持活动状态。该卷最初是空的,Pod 中的容器可以读写 emptyDir 卷中的文件。一旦 Pod 从节点中移除,emptyDir 中的数据就会被擦除。
-
hostPath – 这种类型的卷将文件或目录从主机节点的文件系统挂载到您的 pod 中。
-
gcePersistentDisk – 这种类型的卷将 Google Compute Engine (GCE) 持久磁盘安装到您的 Pod 中。当 Pod 从节点中移除时,gcePersistentDisk 中的数据保持不变。
-
awsElasticBlockStore – 这种类型的卷将 Amazon Web Services (AWS) 弹性块存储安装到您的 Pod 中。就像gcePersistentDisk,在一个数据awsElasticBlockStore当POD从节点取出保持不变。
-
nfs – nfs卷允许将现有的 NFS(网络文件系统)挂载到您的 pod 中。从节点中删除 Pod 时,不会擦除nfs卷中的数据。该卷仅被卸载。
-
iscsi – iscsi卷允许将现有的 iSCSI(SCSI over IP)卷安装到您的 Pod 中。
-
flocker – 它是一个开源集群容器数据卷管理器。它用于管理数据量。甲flocker体积允许Flocker数据集将被安装到吊舱。如果数据集在 Flocker 中不存在,那么首先需要使用 Flocker API 创建它。
-
glusterfs – Glusterfs是一个开放源代码的网络文件系统。glusterfs 卷允许将 glusterfs 卷挂载到您的 pod 中。
-
rbd – RBD 代表 Rados 块设备。一个RBD量允许拉多什块设备的体积被安装到您的吊舱。从节点中删除 Pod 后,数据仍会保留。
-
cephfs – cephfs卷允许将现有的 CephFS 卷挂载到您的 pod 中。从节点中删除 Pod 后,数据保持不变。
-
gitRepo – gitRepo卷挂载一个空目录并将git存储库克隆到其中以供 pod 使用。
-
秘密–秘密卷用于将敏感信息(例如密码)传递给 Pod。
-
persistentVolumeClaim -甲persistentVolumeClaim卷用于一个PersistentVolume安装到吊舱。PersistentVolumes 是用户在不知道特定云环境的详细信息的情况下“声明”持久存储(例如 GCE PersistentDisk 或 iSCSI 卷)的一种方式。
-
downAPI – downAPI卷用于使应用程序可以使用向下的 API 数据。它挂载一个目录并将请求的数据写入纯文本文件。
-
azureDiskVolume – AzureDiskVolume用于将 Microsoft Azure 数据磁盘装入 Pod。
持久卷和持久卷声明
Persistent Volume (PV) – 这是一个由管理员配置的网络存储。它是集群中的一种资源,独立于使用 PV 的任何单个 pod。
持久卷声明 (PVC) – Kubernetes 为其 pod 请求的存储称为 PVC。用户不需要知道底层供应。声明必须在创建 pod 的同一个命名空间中创建。
创建持久卷
kind: PersistentVolume ---------> 1
apiVersion: v1
metadata:
name: pv0001 ------------------> 2
labels:
type: local
spec:
capacity: -----------------------> 3
storage: 10Gi ----------------------> 4
accessModes:
- ReadWriteOnce -------------------> 5
hostPath:
path: "/tmp/data01" --------------------------> 6
在上面的代码中,我们定义了 –
-
kind: PersistentVolume → 我们将 kind 定义为 PersistentVolume,它告诉 kubernetes 正在使用的 yaml 文件是用来创建 Persistent Volume。
-
名称:pv0001 → 我们正在创建的 PersistentVolume 的名称。
-
容量: → 此规范将定义我们尝试创建的 PV 容量。
-
storage: 10Gi → 这告诉底层基础设施我们试图在定义的路径上声明 10Gi 空间。
-
ReadWriteOnce → 这告诉我们正在创建的卷的访问权限。
-
路径:“/tmp/data01” → 这个定义告诉机器我们正试图在底层基础设施上的这个路径下创建卷。
创建光伏
$ kubectl create –f local-01.yaml persistentvolume "pv0001" created
检查光伏
$ kubectl get pv NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 10Gi RWO Available 14s
描述光伏
$ kubectl describe pv pv0001
创建持久卷声明
kind: PersistentVolumeClaim --------------> 1
apiVersion: v1
metadata:
name: myclaim-1 --------------------> 2
spec:
accessModes:
- ReadWriteOnce ------------------------> 3
resources:
requests:
storage: 3Gi ---------------------> 4
在上面的代码中,我们定义了 –
-
kind:PersistentVolumeClaim → 它指示底层基础设施我们正在尝试申请指定数量的空间。
-
名称:myclaim-1 → 我们尝试创建的声明的名称。
-
ReadWriteOnce → 这指定了我们试图创建的声明的模式。
-
storage: 3Gi → 这将告诉 kubernetes 我们试图声明的空间量。
创建PVC
$ kubectl create –f myclaim-1 persistentvolumeclaim "myclaim-1" created
获取有关 PVC 的详细信息
$ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES AGE myclaim-1 Bound pv0001 10Gi RWO 7s
描述PVC
$ kubectl describe pv pv0001
将 PV 和 PVC 与 POD 一起使用
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
name: frontendhttp
spec:
containers:
- name: myfrontend
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts: ----------------------------> 1
- mountPath: "/usr/share/tomcat/html"
name: mypd
volumes: -----------------------> 2
- name: mypd
persistentVolumeClaim: ------------------------->3
claimName: myclaim-1
在上面的代码中,我们定义了 –
-
volumeMounts: → 这是容器中将发生安装的路径。
-
体积: → 这个定义定义了我们要声明的体积定义。
-
PersistentVolumeClaim: → 在此之下,我们定义将在定义的 pod 中使用的卷名称。
Kubernetes – 秘密
Secrets 可以定义为 Kubernetes 对象,用于存储敏感数据,例如加密的用户名和密码。
在 Kubernetes 中有多种创建秘密的方法。
- 从 txt 文件创建。
- 从 yaml 文件创建。
从文本文件创建
为了从文本文件(例如用户名和密码)创建机密,我们首先需要将它们存储在 txt 文件中并使用以下命令。
$ kubectl create secret generic tomcat-passwd –-from-file = ./username.txt –fromfile = ./. password.txt
从 Yaml 文件创建
apiVersion: v1 kind: Secret metadata: name: tomcat-pass type: Opaque data: password: <User Password> username: <User Name>
创建秘密
$ kubectl create –f Secret.yaml secrets/tomcat-pass
使用秘密
一旦我们创建了秘密,它就可以在 pod 或复制控制器中作为 –
- 环境变量
- 体积
作为环境变量
为了使用secret作为环境变量,我们将在pod yaml文件的spec部分下使用env。
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: tomcat-pass
作为体积
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat:7.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"
秘密配置作为环境变量
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
spec:
nodeSelector:
resource-group:
containers:
- name: appname
image:
imagePullPolicy: Always
ports:
- containerPort: 3000
env: -----------------------------> 1
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: tomcat-secrets
在上面的代码中,在env定义下,我们使用 secrets 作为复制控制器中的环境变量。
作为卷挂载的秘密
apiVersion: v1
kind: pod
metadata:
name: appname
spec:
metadata:
name: appname
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat: 8.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"
Kubernetes – 网络策略
网络策略定义了同一命名空间中的 Pod 如何相互通信以及如何与网络端点通信。它需要在 API 服务器的运行时配置中启用extensions/v1beta1/networkpolicies。它的资源使用标签来选择 Pod 并定义规则以允许流量传输到特定 Pod 以及命名空间中定义的特定 Pod。
首先,我们需要配置命名空间隔离策略。基本上,负载均衡器需要这种网络策略。
kind: Namespace
apiVersion: v1
metadata:
annotations:
net.beta.kubernetes.io/network-policy: |
{
"ingress":
{
"isolation": "DefaultDeny"
}
}
$ kubectl annotate ns <namespace> "net.beta.kubernetes.io/network-policy =
{\"ingress\": {\"isolation\": \"DefaultDeny\"}}"
创建命名空间后,我们需要创建网络策略。
网络策略 Yaml
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: allow-frontend
namespace: myns
spec:
podSelector:
matchLabels:
role: backend
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
Kubernetes – API
Kubernetes API 作为系统声明性配置模式的基础。Kubectl命令行工具可用于创建、更新、删除和获取 API 对象。Kubernetes API 充当 Kubernetes 不同组件之间的通信器。
将 API 添加到 Kubernetes
向 Kubernetes 添加新 API 将为 Kubernetes 添加新功能,这将增加 Kubernetes 的功能。然而,与此同时,它也会增加系统的成本和可维护性。为了在成本和复杂性之间取得平衡,为此定义了一些集合。
正在添加的 API 应该对 50% 以上的用户有用。没有其他方法可以在 Kubernetes 中实现该功能。特殊情况在Kubernetes社区会议中讨论,然后添加API。
API 更改
为了增加 Kubernetes 的能力,系统会不断地引入变化。由 Kubernetes 团队完成,在不移除或影响系统现有功能的情况下将功能添加到 Kubernetes。
为了演示一般过程,这是一个(假设的)示例 –
-
用户将 Pod 对象 POST 到/api/v7beta1/…
-
JSON 被解组为v7beta1.Pod结构
-
默认值应用于v7beta1.Pod
-
所述v7beta1.Pod被转换为api.Pod结构
-
该api.Pod验证,任何错误都返回给用户
-
将api.Pod转换为 v6.Pod(因为 v6 是最新的稳定版本)
-
该v6.Pod被整理成JSON并写入ETCD
现在我们已经存储了 Pod 对象,用户可以在任何支持的 API 版本中获取该对象。例如 –
-
用户从/api/v5/…获取 Pod
-
从etcd读取 JSON并解组到v6.Pod结构中
-
默认值应用于v6.Pod
-
所述v6.Pod被转换为api.Pod结构
-
所述api.Pod被转换为v5.Pod结构
-
该v5.Pod被整理成JSON和发送给用户
此过程的含义是 API 更改必须谨慎且向后兼容。
API 版本控制
为了更容易支持多种结构,Kubernetes 支持多个 API 版本,每个版本都位于不同的 API 路径,例如/api/v1或/apsi/extensions/v1beta1
Kubernetes 的版本标准在多个标准中定义。
阿尔法级别
-
此版本包含 alpha(例如 v1alpha1)
-
这个版本可能有问题;启用的版本可能有错误
-
可以随时取消对错误的支持。
-
建议仅用于短期测试,因为支撑可能不会一直存在。
测试级别
-
版本名称包含 beta(例如 v2beta3)
-
代码经过全面测试,启用的版本应该是稳定的。
-
不会放弃对该功能的支持;可能会有一些小的变化。
-
建议仅用于非关键业务用途,因为后续版本中可能会发生不兼容的更改。
稳定水平
-
版本名称是vX,其中X是一个整数。
-
许多后续版本的发布软件中都会出现稳定版本的功能。
Kubernetes – Kubectl
Kubectl 是与 Kubernetes API 交互的命令行实用程序。它是一个用于在 Kubernetes 集群中通信和管理 Pod 的接口。
需要将 kubectl 设置为本地才能与 Kubernetes 集群交互。
设置 Kubectl
使用 curl 命令将可执行文件下载到本地工作站。
在 Linux 上
$ curl -O https://storage.googleapis.com/kubernetesrelease/ release/v1.5.2/bin/linux/amd64/kubectl
在 OS X 工作站上
$ curl -O https://storage.googleapis.com/kubernetesrelease/ release/v1.5.2/bin/darwin/amd64/kubectl
下载完成后,将二进制文件移动到系统路径中。
$ chmod +x kubectl $ mv kubectl /usr/local/bin/kubectl
配置 Kubectl
以下是执行配置操作的步骤。
$ kubectl config set-cluster default-cluster --server = https://${MASTER_HOST} --
certificate-authority = ${CA_CERT}
$ kubectl config set-credentials default-admin --certificateauthority = ${
CA_CERT} --client-key = ${ADMIN_KEY} --clientcertificate = ${
ADMIN_CERT}
$ kubectl config set-context default-system --cluster = default-cluster --
user = default-admin
$ kubectl config use-context default-system
-
将${MASTER_HOST}替换为之前步骤中使用的主节点地址或名称。
-
将${CA_CERT}替换为前面步骤中创建的ca.pem的绝对路径。
-
将${ADMIN_KEY}替换为前面步骤中创建的admin-key.pem的绝对路径。
-
将${ADMIN_CERT}替换为前面步骤中创建的admin.pem的绝对路径。
验证设置
要验证kubectl是否正常工作,请检查 Kubernetes 客户端是否设置正确。
$ kubectl get nodes NAME LABELS STATUS Vipin.com Kubernetes.io/hostname = vipin.mishra.com Ready
Kubernetes – Kubectl 命令
Kubectl控制着 Kubernetes 集群。它是 Kubernetes 的关键组件之一,设置完成后可在任何机器上的工作站上运行。它具有管理集群中节点的能力。
Kubectl命令用于交互和管理 Kubernetes 对象和集群。在本章中,我们将通过 kubectl 讨论在 Kubernetes 中使用的一些命令。
kubectl annotate – 它更新资源上的注释。
$kubectl annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N = VAL_N [--resource-version = version]
例如,
kubectl annotate pods tomcat description = 'my frontend'
kubectl api-versions – 它在集群上打印支持的 API 版本。
$ kubectl api-version;
kubectl apply – 它能够通过文件或标准输入配置资源。
$ kubectl apply –f <filename>
kubectl attach – 这将事物附加到正在运行的容器。
$ kubectl attach <pod> –c <container> $ kubectl attach 123456-7890 -c tomcat-conatiner
kubectl autoscale – 用于自动缩放定义的 pod,例如部署、副本集、复制控制器。
$ kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min = MINPODS] -- max = MAXPODS [--cpu-percent = CPU] [flags] $ kubectl autoscale deployment foo --min = 2 --max = 10
kubectl cluster-info – 它显示集群信息。
$ kubectl cluster-info
kubectl cluster-info dump – 它转储有关集群的相关信息以进行调试和诊断。
$ kubectl cluster-info dump $ kubectl cluster-info dump --output-directory = /path/to/cluster-state
kubectl config – 修改 kubeconfig 文件。
$ kubectl config <SUBCOMMAD> $ kubectl config –-kubeconfig <String of File name>
kubectl config current-context – 它显示当前上下文。
$ kubectl config current-context #deploys the current context
kubectl config delete-cluster – 从 kubeconfig 中删除指定的集群。
$ kubectl config delete-cluster <Cluster Name>
kubectl config delete-context – 从 kubeconfig 中删除指定的上下文。
$ kubectl config delete-context <Context Name>
kubectl config get-clusters – 显示在 kubeconfig 中定义的集群。
$ kubectl config get-cluster $ kubectl config get-cluster <Cluser Name>
kubectl config get-contexts – 描述一个或多个上下文。
$ kubectl config get-context <Context Name>
kubectl config set-cluster – 在 Kubernetes 中设置集群条目。
$ kubectl config set-cluster NAME [--server = server] [--certificateauthority = path/to/certificate/authority] [--insecure-skip-tls-verify = true]
kubectl config set-context – 在 kubernetes 入口点中设置上下文条目。
$ kubectl config set-context NAME [--cluster = cluster_nickname] [-- user = user_nickname] [--namespace = namespace] $ kubectl config set-context prod –user = vipin-mishra
kubectl config set-credentials – 在 kubeconfig 中设置用户条目。
$ kubectl config set-credentials cluster-admin --username = vipin -- password = uXFGweU9l35qcif
kubectl config set – 在 kubeconfig 文件中设置单个值。
$ kubectl config set PROPERTY_NAME PROPERTY_VALUE
kubectl config unset – 它取消设置 kubectl 中的特定组件。
$ kubectl config unset PROPERTY_NAME PROPERTY_VALUE
kubectl config use-context – 在 kubectl 文件中设置当前上下文。
$ kubectl config use-context <Context Name>
kubectl 配置视图
$ kubectl config view
$ kubectl config view –o jsonpath='{.users[?(@.name == "e2e")].user.password}'
kubectl cp – 将文件和目录复制到容器或从容器复制。
$ kubectl cp <Files from source> <Files to Destinatiion> $ kubectl cp /tmp/foo <some-pod>:/tmp/bar -c <specific-container>
kubectl create – 通过文件名或标准输入创建资源。为此,接受 JSON 或 YAML 格式。
$ kubectl create –f <File Name> $ cat <file name> | kubectl create –f -
以同样的方式,我们可以使用create命令和kubectl创建列出的多个事物。
- 部署
- 命名空间
- 配额
- 秘密 docker-registry
- 秘密
- 秘密通用
- 秘密 TLS
- 服务帐户
- 服务集群ip
- 服务负载均衡器
- 服务节点端口
kubectl delete – 按文件名、标准输入、资源和名称删除资源。
$ kubectl delete –f ([-f FILENAME] | TYPE [(NAME | -l label | --all)])
kubectl describe – 描述kubernetes 中的任何特定资源。显示资源或一组资源的详细信息。
$ kubectl describe <type> <type name> $ kubectl describe pod tomcat
kubectl drain – 这用于出于维护目的排出节点。它准备节点进行维护。这会将节点标记为不可用,以便不应为其分配将创建的新容器。
$ kubectl drain tomcat –force
kubectl edit – 用于结束服务器上的资源。这允许直接编辑可以通过命令行工具接收的资源。
$ kubectl edit <Resource/Name | File Name) Ex. $ kubectl edit rc/tomcat
kubectl exec – 这有助于在容器中执行命令。
$ kubectl exec POD <-c CONTAINER > -- COMMAND < args...> $ kubectl exec tomcat 123-5-456 date
kubectl Exposure – 这用于将 Kubernetes 对象(例如 pod、复制控制器和服务)公开为新的 Kubernetes 服务。这有能力通过正在运行的容器或从yaml文件公开它。
$ kubectl expose (-f FILENAME | TYPE NAME) [--port=port] [--protocol = TCP|UDP] [--target-port = number-or-name] [--name = name] [--external-ip = external-ip-ofservice] [--type = type] $ kubectl expose rc tomcat –-port=80 –target-port = 30000 $ kubectl expose –f tomcat.yaml –port = 80 –target-port =
kubectl get – 此命令能够在集群上获取有关 Kubernetes 资源的数据。
$ kubectl get [(-o|--output=)json|yaml|wide|custom-columns=...|custom-columnsfile=...| go-template=...|go-template-file=...|jsonpath=...|jsonpath-file=...] (TYPE [NAME | -l label] | TYPE/NAME ...) [flags]
例如,
$ kubectl get pod <pod name> $ kubectl get service <Service name>
kubectl logs – 它们用于获取 pod 中容器的日志。打印日志可以定义 pod 中的容器名称。如果 POD 只有一个容器,则无需定义其名称。
$ kubectl logs [-f] [-p] POD [-c CONTAINER] Example $ kubectl logs tomcat. $ kubectl logs –p –c tomcat.8
kubectl port-forward – 它们用于将一个或多个本地端口转发到 pod。
$ kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT [...[LOCAL_PORT_N:]REMOTE_PORT_N] $ kubectl port-forward tomcat 3000 4000 $ kubectl port-forward tomcat 3000:5000
kubectl replace – 能够通过文件名或stdin替换资源。
$ kubectl replace -f FILENAME $ kubectl replace –f tomcat.yml $ cat tomcat.yml | kubectl replace –f -
kubectl 滚动更新– 在复制控制器上执行滚动更新。通过一次更新一个 POD,用新的复制控制器替换指定的复制控制器。
$ kubectl rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] -- image = NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC) $ kubectl rolling-update frontend-v1 –f freontend-v2.yaml
kubectl rollout – 它能够管理部署的推出。
$ Kubectl rollout <Sub Command> $ kubectl rollout undo deployment/tomcat
除了上述之外,我们还可以使用 rollout 执行多项任务,例如 –
- 推出历史
- 推出暂停
- 推出简历
- 推出状态
- 推出 撤消
kubectl run – Run 命令能够在 Kubernetes 集群上运行镜像。
$ kubectl run NAME --image = image [--env = "key = value"] [--port = port] [-- replicas = replicas] [--dry-run = bool] [--overrides = inline-json] [--command] -- [COMMAND] [args...] $ kubectl run tomcat --image = tomcat:7.0 $ kubectl run tomcat –-image = tomcat:7.0 –port = 5000
kubectl scale – 它将扩展 Kubernetes 部署、副本集、复制控制器或作业的大小。
$ kubectl scale [--resource-version = version] [--current-replicas = count] -- replicas = COUNT (-f FILENAME | TYPE NAME ) $ kubectl scale –-replica = 3 rs/tomcat $ kubectl scale –replica = 3 tomcat.yaml
kubectl set image – 它更新 pod 模板的图像。
$ kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1 = CONTAINER_IMAGE_1 ... CONTAINER_NAME_N = CONTAINER_IMAGE_N $ kubectl set image deployment/tomcat busybox = busybox ngnix = ngnix:1.9.1 $ kubectl set image deployments, rc tomcat = tomcat6.0 --all
kubectl set resources – 用于设置资源的内容。它使用 pod 模板更新对象的资源/限制。
$ kubectl set resources (-f FILENAME | TYPE NAME) ([--limits = LIMITS & -- requests = REQUESTS] $ kubectl set resources deployment tomcat -c = tomcat -- limits = cpu = 200m,memory = 512Mi
kubectl top node – 它显示 CPU/内存/存储使用情况。top 命令允许您查看节点的资源消耗。
$ kubectl top node [node Name]
同样的命令也可以用于 pod。
Kubernetes – 创建应用程序
为了创建用于 Kubernetes 部署的应用程序,我们需要首先在 Docker 上创建应用程序。这可以通过两种方式完成 –
- 通过下载
- 从 Docker 文件
通过下载
现有镜像可以从 Docker hub 下载,并可以存储在本地 Docker 注册表中。
为此,请运行 Docker pull命令。
$ docker pull --help Usage: docker pull [OPTIONS] NAME[:TAG|@DIGEST] Pull an image or a repository from the registry -a, --all-tags = false Download all tagged images in the repository --help = false Print usage
以下将是上述代码的输出。

上面的屏幕截图显示了一组存储在我们本地 Docker 注册表中的图像。
如果我们想从包含要测试的应用程序的镜像构建容器,我们可以使用 Docker run 命令来完成。
$ docker run –i –t unbunt /bin/bash
从 Docker 文件
为了从 Docker 文件创建应用程序,我们需要首先创建一个 Docker 文件。
以下是 Jenkins Docker 文件的示例。
FROM ubuntu:14.04 MAINTAINER [email protected] ENV REFRESHED_AT 2017-01-15 RUN apt-get update -qq && apt-get install -qqy curl RUN curl https://get.docker.io/gpg | apt-key add - RUN echo deb http://get.docker.io/ubuntu docker main > /etc/apt/↩ sources.list.d/docker.list RUN apt-get update -qq && apt-get install -qqy iptables ca-↩ certificates lxc openjdk-6-jdk git-core lxc-docker ENV JENKINS_HOME /opt/jenkins/data ENV JENKINS_MIRROR http://mirrors.jenkins-ci.org RUN mkdir -p $JENKINS_HOME/plugins RUN curl -sf -o /opt/jenkins/jenkins.war -L $JENKINS_MIRROR/war-↩ stable/latest/jenkins.war RUN for plugin in chucknorris greenballs scm-api git-client git ↩ ws-cleanup ;\ do curl -sf -o $JENKINS_HOME/plugins/${plugin}.hpi \ -L $JENKINS_MIRROR/plugins/${plugin}/latest/${plugin}.hpi ↩ ; done ADD ./dockerjenkins.sh /usr/local/bin/dockerjenkins.sh RUN chmod +x /usr/local/bin/dockerjenkins.sh VOLUME /var/lib/docker EXPOSE 8080 ENTRYPOINT [ "/usr/local/bin/dockerjenkins.sh" ]
创建上述文件后,将其以 Dockerfile 的名称保存并 cd 到文件路径。然后,运行以下命令。

$ sudo docker build -t jamtur01/Jenkins .
镜像构建完成后,我们可以测试镜像是否工作正常,是否可以转换为容器。
$ docker run –i –t jamtur01/Jenkins /bin/bash
Kubernetes – 应用部署
部署是一种将镜像转换为容器,然后将这些镜像分配到 Kubernetes 集群中的 Pod 的方法。这也有助于设置应用程序集群,其中包括服务、pod、复制控制器和副本集的部署。集群可以设置为部署在 pod 上的应用程序可以相互通信。
在这个设置中,我们可以在一个应用程序之上设置一个负载均衡器,将流量转移到一组 Pod,然后它们与后端 Pod 通信。Pod 之间的通信是通过 Kubernetes 内置的服务对象进行的。
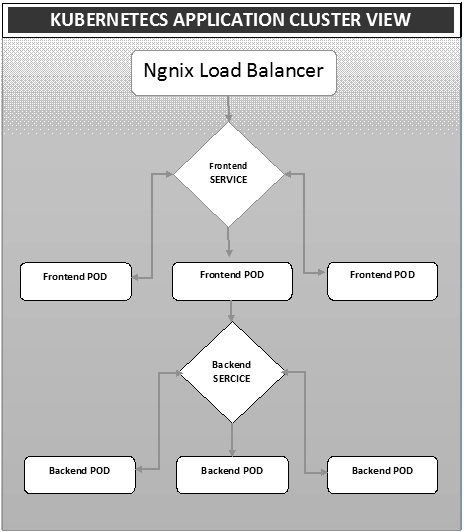
Ngnix 负载均衡器 Yaml 文件
apiVersion: v1
kind: Service
metadata:
name: oppv-dev-nginx
labels:
k8s-app: omni-ppv-api
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: dev
Ngnix 复制控制器 Yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
labels:
k8s-app: appname
component: nginx
env: env_name
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 8080
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: BACKEND_HOST
value: oppv-env_name-node:3000
前端服务 Yaml 文件
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- name: http
port: 3000
protocol: TCP
targetPort: 3000
selector:
k8s-app: appname
component: nodejs
env: dev
前端复制控制器 Yaml 文件
apiVersion: v1
kind: ReplicationController
metadata:
name: Frontend
spec:
replicas: 3
template:
metadata:
name: frontend
labels:
k8s-app: Frontend
component: nodejs
env: Dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 3000
resources:
requests:
memory: "request_mem"
cpu: "limit_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: config-env
后端服务 Yaml 文件
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
k8s-app: backend
spec:
type: NodePort
ports:
- name: http
port: 9010
protocol: TCP
targetPort: 9000
selector:
k8s-app: appname
component: play
env: dev
支持的复制控制器 Yaml 文件
apiVersion: v1
kind: ReplicationController
metadata:
name: backend
spec:
replicas: 3
template:
metadata:
name: backend
labels:
k8s-app: beckend
component: play
env: dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 9000
command: [ "./docker-entrypoint.sh" ]
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
volumeMounts:
- name: config-volume
mountPath: /app/vipin/play/conf
volumes:
- name: config-volume
configMap:
name: appname
Kubernetes – 自动缩放
自动缩放是 Kubernetes 集群的关键特性之一。它是一个特性,其中集群能够随着服务响应需求的增加而增加节点数量,并随着需求的减少而减少节点数量。Google Cloud Engine (GCE) 和 Google Container Engine (GKE) 目前支持这种自动缩放功能,并且很快就会从 AWS 开始。
为了在 GCE 中建立可扩展的基础设施,我们首先需要有一个活动的 GCE 项目,其中包含 Google 云监控、Google 云日志记录和启用堆栈驱动程序的功能。
首先,我们将设置运行在其中的几个节点的集群。完成后,我们需要设置以下环境变量。
环境变量
export NUM_NODES = 2 export KUBE_AUTOSCALER_MIN_NODES = 2 export KUBE_AUTOSCALER_MAX_NODES = 5 export KUBE_ENABLE_CLUSTER_AUTOSCALER = true
完成后,我们将通过运行kube-up.sh来启动集群。这将与集群自动标量添加一起创建集群。
./cluster/kube-up.sh
在创建集群时,我们可以使用以下 kubectl 命令检查我们的集群。
$ kubectl get nodes NAME STATUS AGE kubernetes-master Ready,SchedulingDisabled 10m kubernetes-minion-group-de5q Ready 10m kubernetes-minion-group-yhdx Ready 8m
现在,我们可以在集群上部署一个应用程序,然后启用水平 Pod 自动缩放器。这可以使用以下命令来完成。
$ kubectl autoscale deployment <Application Name> --cpu-percent = 50 --min = 1 -- max = 10
上面的命令表明,随着应用程序负载的增加,我们将维护至少 1 个,最多 10 个 POD 副本。
我们可以通过运行$kubclt get hpa命令来检查autoscaler的状态。我们将使用以下命令增加 Pod 的负载。
$ kubectl run -i --tty load-generator --image = busybox /bin/sh $ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
我们可以检查HPA运行$ kubectl GET百帕命令。
$ kubectl get hpa NAME REFERENCE TARGET CURRENT php-apache Deployment/php-apache/scale 50% 310% MINPODS MAXPODS AGE 1 20 2m $ kubectl get deployment php-apache NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE php-apache 7 7 7 3 4m
我们可以使用以下命令检查正在运行的 Pod 数量。
jsz@jsz-desk2:~/k8s-src$ kubectl get pods php-apache-2046965998-3ewo6 0/1 Pending 0 1m php-apache-2046965998-8m03k 1/1 Running 0 1m php-apache-2046965998-ddpgp 1/1 Running 0 5m php-apache-2046965998-lrik6 1/1 Running 0 1m php-apache-2046965998-nj465 0/1 Pending 0 1m php-apache-2046965998-tmwg1 1/1 Running 0 1m php-apache-2046965998-xkbw1 0/1 Pending 0 1m
最后,我们可以获得节点状态。
$ kubectl get nodes NAME STATUS AGE kubernetes-master Ready,SchedulingDisabled 9m kubernetes-minion-group-6z5i Ready 43s kubernetes-minion-group-de5q Ready 9m kubernetes-minion-group-yhdx Ready 9m
Kubernetes – 仪表板设置
设置 Kubernetes 仪表板涉及几个步骤,其中包含一组所需的工具作为设置的先决条件。
- Docker (1.3+)
- 去 (1.5+)
- nodejs (4.2.2+)
- npm (1.3+)
- 爪哇 (7+)
- 吞咽(3.9+)
- Kubernetes (1.1.2+)
设置仪表板
$ sudo apt-get update && sudo apt-get upgrade Installing Python $ sudo apt-get install python $ sudo apt-get install python3 Installing GCC $ sudo apt-get install gcc-4.8 g++-4.8 Installing make $ sudo apt-get install make Installing Java $ sudo apt-get install openjdk-7-jdk Installing Node.js $ wget https://nodejs.org/dist/v4.2.2/node-v4.2.2.tar.gz $ tar -xzf node-v4.2.2.tar.gz $ cd node-v4.2.2 $ ./configure $ make $ sudo make install Installing gulp $ npm install -g gulp $ npm install gulp
验证版本
Java Version $ java –version java version "1.7.0_91" OpenJDK Runtime Environment (IcedTea 2.6.3) (7u91-2.6.3-1~deb8u1+rpi1) OpenJDK Zero VM (build 24.91-b01, mixed mode) $ node –v V4.2.2 $ npn -v 2.14.7 $ gulp -v [09:51:28] CLI version 3.9.0 $ sudo gcc --version gcc (Raspbian 4.8.4-1) 4.8.4 Copyright (C) 2013 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
安装去
$ git clone https://go.googlesource.com/go $ cd go $ git checkout go1.4.3 $ cd src Building GO $ ./all.bash $ vi /root/.bashrc In the .bashrc export GOROOT = $HOME/go export PATH = $PATH:$GOROOT/bin $ go version go version go1.4.3 linux/arm
安装 Kubernetes 仪表板
$ git clone https://github.com/kubernetes/dashboard.git $ cd dashboard $ npm install -g bower
运行仪表板
$ git clone https://github.com/kubernetes/dashboard.git $ cd dashboard $ npm install -g bower $ gulp serve [11:19:12] Requiring external module babel-core/register [11:20:50] Using gulpfile ~/dashboard/gulpfile.babel.js [11:20:50] Starting 'package-backend-source'... [11:20:50] Starting 'kill-backend'... [11:20:50] Finished 'kill-backend' after 1.39 ms [11:20:50] Starting 'scripts'... [11:20:53] Starting 'styles'... [11:21:41] Finished 'scripts' after 50 s [11:21:42] Finished 'package-backend-source' after 52 s [11:21:42] Starting 'backend'... [11:21:43] Finished 'styles' after 49 s [11:21:43] Starting 'index'... [11:21:44] Finished 'index' after 1.43 s [11:21:44] Starting 'watch'... [11:21:45] Finished 'watch' after 1.41 s [11:23:27] Finished 'backend' after 1.73 min [11:23:27] Starting 'spawn-backend'... [11:23:27] Finished 'spawn-backend' after 88 ms [11:23:27] Starting 'serve'... 2016/02/01 11:23:27 Starting HTTP server on port 9091 2016/02/01 11:23:27 Creating API client for 2016/02/01 11:23:27 Creating Heapster REST client for http://localhost:8082 [11:23:27] Finished 'serve' after 312 ms [BS] [BrowserSync SPA] Running... [BS] Access URLs: -------------------------------------- Local: http://localhost:9090/ External: http://192.168.1.21:9090/ -------------------------------------- UI: http://localhost:3001 UI External: http://192.168.1.21:3001 -------------------------------------- [BS] Serving files from: /root/dashboard/.tmp/serve [BS] Serving files from: /root/dashboard/src/app/frontend [BS] Serving files from: /root/dashboard/src/app
Kubernetes 仪表板
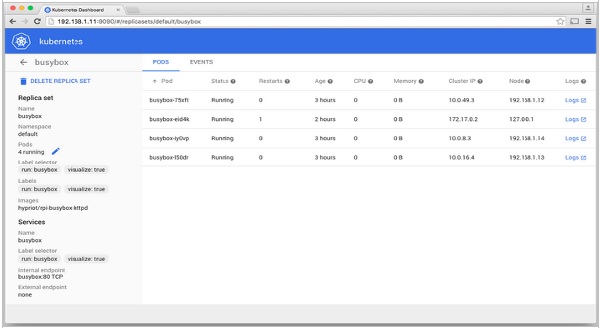
Kubernetes – 监控
监控是管理大型集群的关键组件之一。为此,我们有许多工具。
使用 Prometheus 进行监控
它是一个监控和警报系统。它是在 SoundCloud 构建的,并于 2012 年开源。它很好地处理了多维数据。
Prometheus 有多个组件可以参与监控 –
-
Prometheus – 它是抓取和存储数据的核心组件。
-
Prometheus node explore – 获取主机级矩阵并将它们暴露给 Prometheus。
-
Ranch-eye – 是一个haproxy并将cAdvisor统计数据暴露给Prometheus。
-
Grafana – 数据可视化。
-
InfuxDB – 时间序列数据库,专门用于存储来自牧场主的数据。
-
Prom-ranch-exporter – 这是一个简单的 node.js 应用程序,它有助于查询 Rancher 服务器的服务堆栈状态。
Sematext Docker 代理
它是一个现代 Docker 感知指标、事件和日志收集代理。它在每个 Docker 主机上作为一个小容器运行,并收集所有集群节点和容器的日志、指标和事件。如果核心服务部署在 Docker 容器中,它会发现所有容器(一个 Pod 可能包含多个容器),包括 Kubernetes 核心服务的容器。部署后,所有日志和指标立即可用。
将代理部署到节点
Kubernetes 提供 DeamonSets 以确保将 pod 添加到集群中。
配置 SemaText Docker 代理
它是通过环境变量配置的。
-
如果您还没有,请访问apps.sematext.com获取一个免费帐户。
-
创建一个“Docker”类型的 SPM 应用程序以获取 SPM 应用程序令牌。SPM 应用程序将保存您的 Kubernetes 性能指标和事件。
-
创建Logsene App,获取Logsene App Token。Logsene App 将保存您的 Kubernetes 日志。
-
在 DaemonSet 定义中编辑 LOGSENE_TOKEN 和 SPM_TOKEN 的值,如下所示。
-
获取最新的 sematext-agent-daemonset.yml(原始纯文本)模板(也如下所示)。
-
将其存储在磁盘上的某个位置。
-
将 SPM_TOKEN 和 LOGSENE_TOKEN 占位符替换为您的 SPM 和 Logsene App 令牌。
创建 DaemonSet 对象
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: sematext-agent
spec:
template:
metadata:
labels:
app: sematext-agent
spec:
selector: {}
dnsPolicy: "ClusterFirst"
restartPolicy: "Always"
containers:
- name: sematext-agent
image: sematext/sematext-agent-docker:latest
imagePullPolicy: "Always"
env:
- name: SPM_TOKEN
value: "REPLACE THIS WITH YOUR SPM TOKEN"
- name: LOGSENE_TOKEN
value: "REPLACE THIS WITH YOUR LOGSENE TOKEN"
- name: KUBERNETES
value: "1"
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
- mountPath: /etc/localtime
name: localtime
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
- name: localtime
hostPath:
path: /etc/localtime
使用 kubectl 运行 Sematext Agent Docker
$ kubectl create -f sematext-agent-daemonset.yml daemonset "sematext-agent-daemonset" created
Kubernetes 日志
Kubernetes 容器的日志与 Docker 容器日志没有太大区别。但是,Kubernetes 用户需要查看已部署 Pod 的日志。因此,让特定于 Kubernetes 的信息可用于日志搜索非常有用,例如 –
- Kubernetes 命名空间
- Kubernetes pod 名称
- Kubernetes 容器名称
- Docker 镜像名称
- Kubernetes UID
使用 ELK 堆栈和 LogSpout
ELK 堆栈包括 Elasticsearch、Logstash 和 Kibana。为了收集日志并将日志转发到日志平台,我们将使用 LogSpout(尽管还有其他选项,例如 FluentD)。
以下代码展示了如何在 Kubernetes 上设置 ELK 集群并为 ElasticSearch 创建服务 –
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCP
创建复制控制器
apiVersion: v1
kind: ReplicationController
metadata:
name: es
namespace: elk
labels:
component: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
spec:
serviceAccount: elasticsearch
containers:
- name: es
securityContext:
capabilities:
add:
- IPC_LOCK
image: quay.io/pires/docker-elasticsearch-kubernetes:1.7.1-4
env:
- name: KUBERNETES_CA_CERTIFICATE_FILE
value: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "CLUSTER_NAME"
value: "myesdb"
- name: "DISCOVERY_SERVICE"
value: "elasticsearch"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "true"
- name: HTTP_ENABLE
value: "true"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
volumeMounts:
- mountPath: /data
name: storage
volumes:
- name: storage
emptyDir: {}
Kibana 网址
对于 Kibana,我们提供 Elasticsearch URL 作为环境变量。
- name: KIBANA_ES_URL value: "http://elasticsearch.elk.svc.cluster.local:9200" - name: KUBERNETES_TRUST_CERT value: "true"
Kibana UI 将可以在容器端口 5601 和相应的主机/节点端口组合处访问。开始时,Kibana 中不会有任何数据(这是意料之中的,因为您尚未推送任何数据)。
