Logstash – 快速指南
Logstash – 快速指南
Logstash – 简介
Logstash 是一种基于过滤器/管道模式的工具,用于收集、处理和生成日志或事件。它有助于集中和实时分析来自不同来源的日志和事件。
Logstash 是用运行在 JVM 上的 JRuby 编程语言编写的,因此您可以在不同的平台上运行 Logstash。它从几乎所有类型的来源收集不同类型的数据,如日志、数据包、事件、事务、时间戳数据等。数据源可以是社交数据、电子商务、新闻文章、CRM、游戏数据、网络趋势、金融数据、物联网、移动设备等。
Logstash 一般特性
Logstash 的一般功能如下 –
-
Logstash 可以从不同来源收集数据并发送到多个目的地。
-
Logstash 可以处理所有类型的日志数据,如 Apache 日志、Windows 事件日志、网络协议数据、标准输入数据等等。
-
Logstash 还可以处理 http 请求和响应数据。
-
Logstash 提供了多种过滤器,可以帮助用户通过解析和转换数据来发现数据中的更多含义。
-
Logstash 还可用于处理物联网中的传感器数据。
-
Logstash 是开源的,在 Apache 许可版本 2.0 下可用。
Logstash 关键概念
Logstash 的关键概念如下 –
事件对象
它是 Logstash 中的主要对象,它封装了 Logstash 管道中的数据流。Logstash 使用此对象来存储输入数据并添加在过滤阶段创建的额外字段。
Logstash 为开发人员提供了一个事件 API 来操作事件。在本教程中,此事件被称为记录数据事件、日志事件、日志数据、输入日志数据、输出日志数据等各种名称。
管道
它由 Logstash 中从输入到输出的数据流阶段组成。输入数据进入管道并以事件的形式进行处理。然后以用户或终端系统所需的格式发送到输出目的地。
输入
这是 Logstash 管道中的第一阶段,用于获取 Logstash 中的数据以进行进一步处理。Logstash 提供了各种插件来从不同平台获取数据。一些最常用的插件是——文件、系统日志、Redis 和 Beats。
筛选
这是 Logstash 的中间阶段,事件的实际处理发生在这里。开发人员可以使用 Logstash 预定义的正则表达式模式来创建序列,以区分事件中的字段和接受的输入事件的标准。
Logstash 提供了各种插件来帮助开发人员解析事件并将其转换为理想的结构。一些最常用的过滤器插件是 – Grok、Mutate、Drop、Clone 和 Geoip。
输出
这是 Logstash 管道的最后一个阶段,在此阶段可以将输出事件格式化为目标系统所需的结构。最后,它使用插件将完成处理后的输出事件发送到目的地。一些最常用的插件是 – Elasticsearch、File、Graphite、Statsd 等。
Logstash 优势
以下几点说明了Logstash的各种优势。
-
Logstash 提供正则表达式模式序列来识别和解析任何输入事件中的各种字段。
-
Logstash 支持各种用于提取日志数据的 Web 服务器和数据源。
-
Logstash 提供了多个插件来解析日志数据并将其转换为任何用户所需的格式。
-
Logstash 是集中式的,这使得处理和收集来自不同服务器的数据变得容易。
-
Logstash 支持许多数据库、网络协议和其他服务作为日志事件的目标源。
-
Logstash 使用 HTTP 协议,这使得用户可以升级 Elasticsearch 版本,而无需在锁定步骤中升级 Logstash。
Logstash 的缺点
以下几点解释了Logstash的各种缺点。
-
Logstash 使用 http,这会对日志数据的处理产生负面影响。
-
使用 Logstash 有时可能有点复杂,因为它需要对输入日志数据有很好的理解和分析。
-
过滤器插件不是通用的,因此,用户可能需要找到正确的模式序列以避免解析错误。
在下一章中,我们将了解 ELK Stack 是什么以及它如何帮助 Logstash。
Logstash – ELK 堆栈
ELK 代表Elasticsearch、Logstash和Kibana。在 ELK 堆栈中,Logstash 从不同的输入源中提取日志数据或其他事件。它处理事件,然后将其存储在 Elasticsearch 中。Kibana 是一个 Web 界面,它访问来自 Elasticsearch 的日志数据并将其可视化。
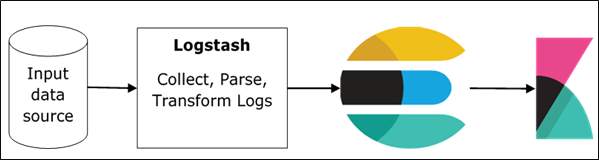
Logstash 和 Elasticsearch
Logstash 提供了输入输出 Elasticsearch 插件来读写日志事件到 Elasticsearch。Elasticsearch 公司也推荐将 Elasticsearch 作为输出目的地,因为它与 Kibana 兼容。Logstash 通过 http 协议将数据发送到 Elasticsearch。
Elasticsearch 提供批量上传功能,有助于将来自不同来源或 Logstash 实例的数据上传到集中式 Elasticsearch 引擎。ELK 与其他 DevOps 解决方案相比具有以下优势 –
-
ELK 堆栈更易于管理,并且可以扩展以处理 PB 级的事件。
-
ELK 堆栈架构非常灵活,它提供了与 Hadoop 的集成。Hadoop 主要用于归档目的。Logstash 可以使用flume 直接连接Hadoop,Elasticsearch 提供了一个名为es-hadoop的连接器来连接Hadoop。
-
ELK 拥有的总成本远低于其替代品。
Logstash 和 Kibana
Kibana 不直接与 Logstash 交互,而是通过数据源,即 ELK 堆栈中的 Elasticsearch。Logstash 从每个来源收集数据,Elasticsearch 以非常快的速度对其进行分析,然后 Kibana 提供有关该数据的可操作见解。
Kibana 是一个基于 Web 的可视化工具,它可以帮助开发人员和其他人在 Elasticsearch 引擎中分析 Logstash 收集的大量事件的变化。这种可视化使预测或查看输入源的错误或其他重要事件趋势的变化变得容易。
Logstash – 安装
要在系统上安装 Logstash,我们应该按照以下步骤操作 –
步骤 1 – 检查计算机中安装的 Java 版本;它应该是 Java 8,因为它与 Java 9 不兼容。您可以通过以下方式检查:
在 Windows 操作系统 (OS) 中(使用命令提示符) –
> java -version
在 UNIX 操作系统中(使用终端) –
$ echo $JAVA_HOME
第 2 步– 从以下位置下载 Logstash –
https://www.elastic.co/downloads/logstash。
-
对于 Windows 操作系统,下载 ZIP 文件。
-
对于 UNIX 操作系统,下载 TAR 文件。
-
对于 Debian 操作系统,请下载 DEB 文件。
-
对于 Red Hat 和其他 Linux 发行版,请下载 RPN 文件。
-
APT 和 Yum 实用程序也可用于在许多 Linux 发行版中安装 Logstash。
步骤 3 – Logstash 的安装过程非常简单。让我们看看如何在不同平台上安装 Logstash。
注意– 不要在安装文件夹中放置任何空格或冒号。
-
Windows 操作系统– 解压缩 zip 包并安装 Logstash。
-
UNIX OS – 在任何位置提取 tar 文件并安装 Logstash。
$tar –xvf logstash-5.0.2.tar.gz
为 Linux 操作系统使用 APT 实用程序 –
- 下载并安装公共签名密钥 –
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
- 保存存储库定义 –
$ echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.list
- 运行更新 –
$ sudo apt-get update
- 现在您可以使用以下命令进行安装 –
$ sudo apt-get install logstash
为 Debian Linux 操作系统使用 YUM 实用程序–
- 下载并安装公共签名密钥 –
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
-
在您的“/etc/yum.repos.d/”目录中的带有 .repo 后缀的文件中添加以下文本。例如,logstash.repo
[logstash-5.x] name = Elastic repository for 5.x packages baseurl = https://artifacts.elastic.co/packages/5.x/yum gpgcheck = 1 gpgkey = https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled = 1 autorefresh = 1 type = rpm-md
- 您现在可以使用以下命令安装 Logstash –
$ sudo yum install logstash
步骤 4 – 转到 Logstash 主目录。在 bin 文件夹内,在 Windows 的情况下运行elasticsearch.bat文件,或者您可以使用命令提示符和通过终端执行相同操作。在 UNIX 中,运行 Logstash 文件。
我们需要指定输入源、输出源和可选过滤器。为了验证安装,您可以通过使用标准输入流 (stdin) 作为输入源和标准输出流 (stdout) 作为输出源,使用基本配置运行它。您也可以使用-e选项在命令行中指定配置。
在 Windows 中 –
> cd logstash-5.0.1/bin
> Logstash -e 'input { stdin { } } output { stdout {} }'
在 Linux 中 –
$ cd logstash-5.0.1/bin
$ ./logstash -e 'input { stdin { } } output { stdout {} }'
注意– 在 Windows 的情况下,您可能会收到一个错误,指出 JAVA_HOME 未设置。为此,请将其在环境变量中设置为“C:\Program Files\Java\jre1.8.0_111”或您安装 java 的位置。
第 5 步– Logstash Web 界面的默认端口是 9600 到 9700,在logstash-5.0.1\config\logstash.yml 中定义为http.port,它将选择给定范围内的第一个可用端口。
我们可以通过浏览http://localhost:9600或端口是否不同来检查 Logstash 服务器是否已启动并运行,然后请检查命令提示符或终端。我们可以看到分配的端口为“成功启动 Logstash API 端点 {:port ⇒ 9600}。它将以以下方式返回一个 JSON 对象,其中包含有关已安装 Logstash 的信息 –
{
"host":"manu-PC",
"version":"5.0.1",
"http_address":"127.0.0.1:9600",
"build_date":"2016-11-11T22:28:04+00:00",
"build_sha":"2d8d6263dd09417793f2a0c6d5ee702063b5fada",
"build_snapshot":false
}
Logstash – 内部架构
在本章中,我们将讨论 Logstash 的内部架构和不同组件。
Logstash 服务架构
Logstash 处理来自不同服务器和数据源的日志,它充当托运人。托运人用于收集日志,这些日志安装在每个输入源中。像Redis、Kafka或RabbitMQ这样的代理是为索引器保存数据的缓冲区,可能有多个代理作为故障转移实例。
像Lucene这样的索引器用于索引日志以获得更好的搜索性能,然后输出存储在 Elasticsearch 或其他输出目的地。输出存储中的数据可用于 Kibana 和其他可视化软件。
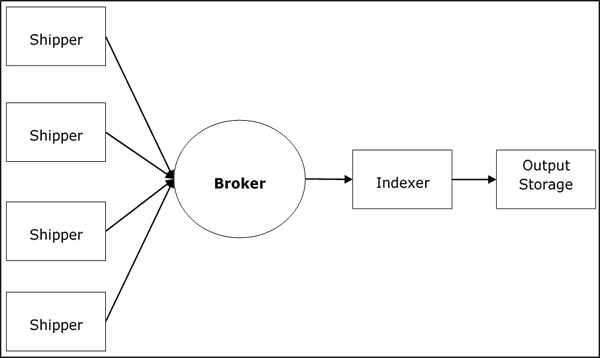
Logstash 内部架构
Logstash 管道由三个组件Input、Filters和Output 组成。输入部分负责指定和访问Apache Tomcat Server的日志文件夹等输入数据源。
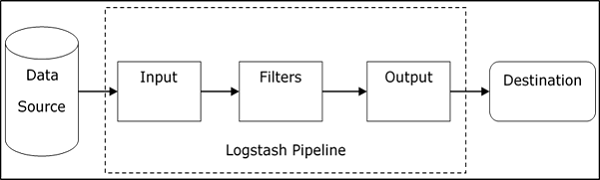
解释 Logstash 管道的示例
Logstash 配置文件包含有关 Logstash 三个组件的详细信息。在本例中,我们将创建一个名为Logstash.conf的文件名。
以下配置从输入日志“inlog.log”中捕获数据并将其写入输出日志“outlog.log”,而没有任何过滤器。
配置文件
Logstash 配置文件只是使用输入插件从inlog.log文件中复制数据,并使用输出插件将日志数据刷新到outlog.log文件中。
input {
file {
path => "C:/tpwork/logstash/bin/log/inlog.log"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/outlog.log"
}
}
运行 Logstash
Logstash 使用–f选项指定配置文件。
C:\logstash\bin> logstash –f logstash.conf
日志文件
以下代码块显示了输入日志数据。
Hello tutorialspoint.com
输出日志
Logstash 输出包含消息字段中的输入数据。Logstash 还向输出添加了其他字段,如时间戳、输入源路径、版本、主机和标签。
{
"path":"C:/tpwork/logstash/bin/log/inlog1.log",
"@timestamp":"2016-12-13T02:28:38.763Z",
"@version":"1", "host":"Dell-PC",
"message":" Hello tutorialspoint.com", "tags":[]
}
尽你所能,Logstash 的输出包含的不仅仅是通过输入日志提供的数据。输出包含源路径、时间戳、版本、主机名和标签,用于表示错误等额外消息。
我们可以使用过滤器来处理数据并使其对我们的需求有用。在下一个示例中,我们使用过滤器来获取数据,这将输出限制为仅带有动词(如 GET 或 POST 后跟唯一资源标识符)的数据。
配置文件
在这种Logstash配置中,我们将其命名添加过滤器神交滤除输入数据。与模式序列输入日志匹配的输入日志事件只会错误地到达输出目的地。Logstash 在输出事件中添加了一个名为“_grokparsefailure”的标签,该标签与 grok 过滤器模式序列不匹配。
Logstash 提供了许多内置的正则表达式模式来解析流行的服务器日志,比如 Apache。这里使用的模式需要一个动词,如 get、post 等,后跟一个统一的资源标识符。
input {
file {
path => "C:/tpwork/logstash/bin/log/inlog2.log"
}
}
filter {
grok {
match => {"message" => "%{WORD:verb} %{URIPATHPARAM:uri}"}
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/outlog2.log"
}
}
运行 Logstash
我们可以使用以下命令运行 Logstash。
C:\logstash\bin> logstash –f Logstash.conf
inlog2.log
我们的输入文件包含两个由默认分隔符分隔的事件,即新行分隔符。第一个事件与 GROk 中指定的模式匹配,第二个不匹配。
GET /tutorialspoint/Logstash Input 1234
outlog2.log
我们可以看到第二个输出事件包含“_grokparsefailure”标签,因为它与 grok 过滤器模式不匹配。用户还可以使用输出插件中的“if”条件在输出中删除这些不匹配的事件。
{
"path":"C:/tpwork/logstash/bin/log/inlog2.log",
"@timestamp":"2016-12-13T02:47:10.352Z","@version":"1","host":"Dell-PC","verb":"GET",
"message":"GET /tutorialspoint/logstash", "uri":"/tutorialspoint/logstash", "tags":[]
}
{
"path":"C:/tpwork/logstash/bin/log/inlog2.log",
"@timestamp":"2016-12-13T02:48:12.418Z", "@version":"1", "host":"Dell-PC",
"message":"t 1234\r", "tags":["_grokparsefailure"]
}
Logstash – 收集日志
来自不同服务器或数据源的日志是使用托运人收集的。Shipper 是安装在服务器中的 Logstash 实例,它访问服务器日志并发送到特定的输出位置。
它主要将输出发送到 Elasticsearch 进行存储。Logstash 从以下来源获取输入 –
- 标准输入
- 系统日志
- 文件
- TCP/UDP
- Microsoft Windows 事件日志
- 网络套接字
- 零米
- 定制扩展
使用 Apache Tomcat 7 服务器收集日志
在这个例子中,我们使用文件输入插件收集安装在 windows 中的 Apache Tomcat 7 服务器的日志,并将它们发送到另一个日志。
日志文件
这里配置Logstash访问本地安装的Apache Tomcat 7的访问日志。在文件插件的路径设置中使用正则表达式模式从日志文件中获取数据。这在其名称中包含“访问”并添加了 apache 类型,这有助于将 apache 事件与集中目标源中的其他事件区分开来。最后,输出事件将显示在 output.log 中。
input {
file {
path => "C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/*access*"
type => "apache"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}
运行 Logstash
我们可以使用以下命令运行 Logstash。
C:\logstash\bin> logstash –f Logstash.conf
Apache Tomcat 日志
访问 Apache Tomcat 服务器及其 Web 应用程序 ( http://localhost:8080 ) 以生成日志。日志中更新的数据由 Logstash 实时读取,并按照配置文件中的指定存储在 output.log 中。
Apache Tomcat 根据日期生成一个新的访问日志文件,并在那里记录访问事件。在我们的例子中,它是Apache Tomcat的日志目录中的localhost_access_log.2016-12-24.txt 。
0:0:0:0:0:0:0:1 - - [ 25/Dec/2016:18:37:00 +0800] "GET / HTTP/1.1" 200 11418 0:0:0:0:0:0:0:1 - munish [ 25/Dec/2016:18:37:02 +0800] "GET /manager/html HTTP/1.1" 200 17472 0:0:0:0:0:0:0:1 - - [ 25/Dec/2016:18:37:08 +0800] "GET /docs/ HTTP/1.1" 200 19373 0:0:0:0:0:0:0:1 - - [ 25/Dec/2016:18:37:10 +0800] "GET /docs/introduction.html HTTP/1.1" 200 15399
输出日志
您可以在输出事件中看到,添加了一个类型字段,并且该事件存在于消息字段中。
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt",
"@timestamp":"2016-12-25T10:37:00.363Z","@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - - [25/Dec/2016:18:37:00 +0800] \"GET /
HTTP/1.1\" 200 11418\r","type":"apache","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt","@timestamp":"2016-12-25T10:37:10.407Z",
"@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - munish [25/Dec/2016:18:37:02 +0800] \"GET /
manager/html HTTP/1.1\" 200 17472\r","type":"apache","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt","@timestamp":"2016-12-25T10:37:10.407Z",
"@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - - [25/Dec/2016:18:37:08 +0800] \"GET /docs/
HTTP/1.1\" 200 19373\r","type":"apache","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt","@timestamp":"2016-12-25T10:37:20.436Z",
"@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - - [25/Dec/2016:18:37:10 +0800] \"GET /docs/
introduction.html HTTP/1.1\" 200 15399\r","type":"apache","tags":[]
}
使用 STDIN 插件收集日志
在本节中,我们将讨论使用STDIN 插件收集日志的另一个示例。
日志文件
这是一个非常简单的示例,其中 Logstash 正在读取用户在标准输入中输入的事件。在我们的例子中,它是命令提示符,它将事件存储在 output.log 文件中。
input {
stdin{}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}
运行 Logstash
我们可以使用以下命令运行 Logstash。
C:\logstash\bin> logstash –f Logstash.conf
在命令提示符中写入以下文本 –
用户输入了以下两行。Logstash 通过分隔符设置分隔事件,其默认值为 ‘\n’。用户可以通过更改文件插件中分隔符的值来更改。
Tutorialspoint.com welcomes you Simply easy learning
输出日志
以下代码块显示了输出日志数据。
{
"@timestamp":"2016-12-25T11:41:16.518Z","@version":"1","host":"Dell-PC",
"message":"tutrialspoint.com welcomes you\r","tags":[]
}
{
"@timestamp":"2016-12-25T11:41:53.396Z","@version":"1","host":"Dell-PC",
"message":"simply easy learning\r","tags":[]
}
Logstash – 支持的输入
Logstash 支持来自不同来源的大量日志。它正在与著名的来源合作,如下所述。
从指标收集日志
系统事件和其他时间活动记录在指标中。Logstash 可以从系统指标访问日志并使用过滤器处理它们。这有助于以自定义方式向用户显示事件的实时提要。根据指标过滤器的flush_interval设置和默认情况下刷新指标;设置为 5 秒。
我们通过收集和分析通过 Logstash 运行的事件并在命令提示符上显示实时提要来跟踪 Logstash 生成的测试指标。
日志文件
此配置包含一个生成器插件,由 Logstash 提供用于测试指标并将类型设置设置为“生成”以进行解析。在过滤阶段,我们仅使用“if”语句处理具有生成类型的行。然后,指标插件计算仪表设置中指定的字段。指标插件在flush_interval 中指定的每 5 秒后刷新计数。
最后,使用编解码器插件将过滤器事件输出到标准输出,如命令提示符以进行格式化。Codec 插件使用 [ events ][ rate_1m ] 值在 1 分钟滑动窗口中输出每秒事件。
input {
generator {
type => "generated"
}
}
filter {
if [type] == "generated" {
metrics {
meter => "events"
add_tag => "metric"
}
}
}
output {
# only emit events with the 'metric' tag
if "metric" in [tags] {
stdout {
codec => line { format => "rate: %{[events][rate_1m]}"
}
}
}
运行 Logstash
我们可以使用以下命令运行 Logstash。
>logsaths –f logstash.conf
标准输出(命令提示符)
rate: 1308.4 rate: 1308.4 rate: 1368.654529135342 rate: 1416.4796003951449 rate: 1464.974293984808 rate: 1523.3119444107458 rate: 1564.1602979542715 rate: 1610.6496496890895 rate: 1645.2184750334154 rate: 1688.7768007612485 rate: 1714.652283095914 rate: 1752.5150680019278 rate: 1785.9432934744932 rate: 1806.912181962126 rate: 1836.0070454626025 rate: 1849.5669494173826 rate: 1871.3814756851832 rate: 1883.3443123790712 rate: 1906.4879113216743 rate: 1925.9420717997118 rate: 1934.166137658981 rate: 1954.3176526556897 rate: 1957.0107444542625
从 Web 服务器收集日志
Web 服务器会生成大量有关用户访问和错误的日志。Logstash 有助于使用输入插件从不同服务器提取日志并将它们存储在一个集中位置。
我们正在从本地 Apache Tomcat 服务器的stderr 日志中提取数据并将其存储在 output.log 中。
日志文件
这个 Logstash 配置文件指示 Logstash 读取 apache 错误日志并添加一个名为“apache-error”的标签。我们可以简单地使用文件输出插件将它发送到 output.log。
input {
file {
path => "C:/Program Files/Apache Software Foundation/Tomcat 7.0 /logs/*stderr*"
type => "apache-error"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}
运行 Logstash
我们可以使用以下命令运行 Logstash。
>Logstash –f Logstash.conf
输入日志示例
这是示例stderr 日志,它在 Apache Tomcat 中发生服务器事件时生成。
C:\Program Files\Apache Software Foundation\Tomcat 7.0\logs\ tomcat7-stderr.2016-12-25.log
Dec 25, 2016 7:05:14 PM org.apache.coyote.AbstractProtocol start INFO: Starting ProtocolHandler ["http-bio-9999"] Dec 25, 2016 7:05:14 PM org.apache.coyote.AbstractProtocol start INFO: Starting ProtocolHandler ["ajp-bio-8009"] Dec 25, 2016 7:05:14 PM org.apache.catalina.startup.Catalina start INFO: Server startup in 823 ms
输出日志
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"Dec 25, 2016 7:05:14 PM org.apache.coyote.AbstractProtocol start\r",
"type":"apache-error","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"INFO: Starting ProtocolHandler [
\"ajp-bio-8009\"]\r","type":"apache-error","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"Dec 25, 2016 7:05:14 PM org.apache.catalina.startup.Catalina start\r",
"type":"apache-error","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"INFO: Server startup in 823 ms\r","type":"apache-error","tags":[]
}
从数据源收集日志
首先,让我们了解如何配置 MySQL 进行日志记录。在[mysqld]下MySQL数据库服务器的my.ini文件中添加以下几行。
在 Windows 中,它存在于 MySQL 的安装目录中,位于 –
C:\wamp\bin\mysql\mysql5.7.11
在 UNIX 中,您可以在 -/etc/mysql/my.cnf 中找到它
general_log_file = "C:/wamp/logs/queries.log" general_log = 1
日志文件
在这个配置文件中,file plugin 用于读取 MySQL 日志并将其写入 ouput.log。
input {
file {
path => "C:/wamp/logs/queries.log"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}
查询日志
这是在 MySQL 数据库中执行的查询生成的日志。
2016-12-25T13:05:36.854619Z 2 Query select * from test1_users 2016-12-25T13:05:51.822475Z 2 Query select count(*) from users 2016-12-25T13:05:59.998942Z 2 Query select count(*) from test1_users
输出日志
{
"path":"C:/wamp/logs/queries.log","@timestamp":"2016-12-25T13:05:37.905Z",
"@version":"1","host":"Dell-PC",
"message":"2016-12-25T13:05:36.854619Z 2 Query\tselect * from test1_users",
"tags":[]
}
{
"path":"C:/wamp/logs/queries.log","@timestamp":"2016-12-25T13:05:51.938Z",
"@version":"1","host":"Dell-PC",
"message":"2016-12-25T13:05:51.822475Z 2 Query\tselect count(*) from users",
"tags":[]
}
{
"path":"C:/wamp/logs/queries.log","@timestamp":"2016-12-25T13:06:00.950Z",
"@version":"1","host":"Dell-PC",
"message":"2016-12-25T13:05:59.998942Z 2 Query\tselect count(*) from test1_users",
"tags":[]
}
Logstash – 解析日志
Logstash 使用输入插件接收日志,然后使用过滤器插件来解析和转换数据。日志的解析和转换是根据输出目的地中存在的系统执行的。Logstash 解析日志数据并仅转发必填字段。稍后,这些字段被转换为目标系统的兼容且可理解的形式。
如何解析日志?
日志的解析是使用GROK(知识的图形表示)模式执行的,您可以在 Github 中找到它们 –
https://github.com/elastic/logstash/tree/v1.4.2/patterns。
Logstash 将日志数据与指定的 GROK Pattern 或 Pattern 序列匹配,用于解析日志,例如“%{COMBINEDAPACHELOG}”,通常用于 apache 日志。
解析后的数据更加结构化,易于搜索和执行查询。Logstash 在输入日志中搜索指定的 GROK 模式并从日志中提取匹配的行。您可以使用 GROK 调试器来测试您的 GROK 模式。
GROK 模式的语法是 %{SYNTAX:SEMANTIC}。Logstash GROK 过滤器采用以下形式编写 –
%{PATTERN:FieldName}
这里,PATTERN 代表 GROK 模式,fieldname 是字段的名称,它代表输出中解析的数据。
例如,使用在线 GROK 调试器https://grokdebug.herokuapp.com/
输入
日志中的示例错误行 –
[Wed Dec 07 21:54:54.048805 2016] [:error] [pid 1234:tid 3456829102] [client 192.168.1.1:25007] JSP Notice: Undefined index: abc in /home/manu/tpworks/tutorialspoint.com/index.jsp on line 11
GROK 模式序列
此 GROK 模式序列与日志事件匹配,其中包含时间戳,后跟日志级别、进程 ID、事务 ID 和错误消息。
\[(%{DAY:day} %{MONTH:month} %{MONTHDAY} %{TIME} %{YEAR})\] \[.*:%{LOGLEVEL:loglevel}\]
\[pid %{NUMBER:pid}:tid %{NUMBER:tid}\] \[client %{IP:clientip}:.*\]
%{GREEDYDATA:errormsg}
输出
输出为 JSON 格式。
{
"day": [
"Wed"
],
"month": [
"Dec"
],
"loglevel": [
"error"
],
"pid": [
"1234"
],
"tid": [
"3456829102"
],
"clientip": [
"192.168.1.1"
],
"errormsg": [
"JSP Notice: Undefined index: abc in
/home/manu/tpworks/tutorialspoint.com/index.jsp on line 11"
]
}
Logstash – 过滤器
Logstash 在输入和输出之间的管道中间使用过滤器。Logstash 度量的过滤器操作和创建事件,如Apache-Access。许多过滤器插件用于管理 Logstash 中的事件。在这里,在Logstash 聚合过滤器的示例中,我们过滤数据库中每个 SQL 事务的持续时间并计算总时间。
安装聚合过滤器插件
使用 Logstash-plugin 实用程序安装聚合过滤器插件。Logstash-plugin 是 Logstash 中bin 文件夹中windows 的批处理文件。
>logstash-plugin install logstash-filter-aggregate
日志文件
在此配置中,您可以看到三个用于初始化、递增和生成事务总持续时间的“if”语句,即sql_duration。聚合插件用于添加 sql_duration,存在于输入日志的每个事件中。
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} -
%{NOTSPACE:taskid} - %{NOTSPACE:logger} -
%{WORD:label}( - %{INT:duration:int})?"
]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}
运行 Logstash
我们可以使用以下命令运行 Logstash。
>logstash –f logstash.conf
输入日志
以下代码块显示了输入日志数据。
INFO - 48566 - TRANSACTION_START - start INFO - 48566 - SQL - transaction1 - 320 INFO - 48566 - SQL - transaction1 - 200 INFO - 48566 - TRANSACTION_END - end
输出日志
如配置文件中所指定,记录器所在的最后一个“if”语句 – TRANSACTION_END,它打印总事务时间或 sql_duration。这已在 output.log 中以黄色突出显示。
{
"path":"C:/tpwork/logstash/bin/log/input.log","@timestamp": "2016-12-22T19:04:37.214Z",
"loglevel":"INFO","logger":"TRANSACTION_START","@version": "1","host":"wcnlab-PC",
"message":"8566 - TRANSACTION_START - start\r","tags":[]
}
{
"duration":320,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-22T19:04:38.366Z","loglevel":"INFO","logger":"SQL",
"@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 320\r","taskid":"48566","tags":[]
}
{
"duration":200,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-22T19:04:38.373Z","loglevel":"INFO","logger":"SQL",
"@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 200\r","taskid":"48566","tags":[]
}
{
"sql_duration":520,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-22T19:04:38.380Z","loglevel":"INFO","logger":"TRANSACTION_END",
"@version":"1","host":"wcnlab-PC","label":"end",
"message":" INFO - 48566 - TRANSACTION_END - end\r","taskid":"48566","tags":[]
}
Logstash – 转换日志
Logstash 提供了各种插件来转换解析的日志。这些插件可以在日志中添加、删除和更新字段,以便在输出系统中更好地理解和查询。
我们正在使用Mutate 插件在输入日志的每一行中添加一个字段名称 user。
安装 Mutate 过滤器插件
安装 mutate 过滤器插件;我们可以使用以下命令。
>Logstash-plugin install Logstash-filter-mutate
日志文件
在这个配置文件中,Mutate Plugin 添加在 Aggregate Plugin 之后添加一个新字段。
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [ "message", "%{LOGLEVEL:loglevel} -
%{NOTSPACE:taskid} - %{NOTSPACE:logger} -
%{WORD:label}( - %{INT:duration:int})?" ]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
mutate {
add_field => {"user" => "tutorialspoint.com"}
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}
运行 Logstash
我们可以使用以下命令运行 Logstash。
>logstash –f logstash.conf
输入日志
以下代码块显示了输入日志数据。
INFO - 48566 - TRANSACTION_START - start INFO - 48566 - SQL - transaction1 - 320 INFO - 48566 - SQL - transaction1 - 200 INFO - 48566 - TRANSACTION_END - end
输出日志
您可以看到输出事件中有一个名为“user”的新字段。
{
"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.383Z",
"@version":"1",
"host":"wcnlab-PC",
"message":"NFO - 48566 - TRANSACTION_START - start\r",
"user":"tutorialspoint.com","tags":["_grokparsefailure"]
}
{
"duration":320,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.383Z","loglevel":"INFO","logger":"SQL",
"@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 320\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
{
"duration":200,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.399Z","loglevel":"INFO",
"logger":"SQL","@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 200\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
{
"sql_duration":520,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.399Z","loglevel":"INFO",
"logger":"TRANSACTION_END","@version":"1","host":"wcnlab-PC","label":"end",
"message":" INFO - 48566 - TRANSACTION_END - end\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
Logstash – 输出阶段
输出是 Logstash 管道的最后一个阶段,它将过滤器数据从输入日志发送到指定的目的地。Logstash 提供多个输出插件,将过滤后的日志事件存储到各种不同的存储和搜索引擎。
存储日志
Logstash 可以将过滤后的日志存储在File、Elasticsearch Engine、stdout、AWS CloudWatch等中。TCP、UDP、Websocket等网络协议也可以在 Logstash 中用于将日志事件传输到远程存储系统。
在 ELK 堆栈中,用户使用 Elasticsearch 引擎来存储日志事件。在下面的示例中,我们将为本地 Elasticsearch 引擎生成日志事件。
安装 Elasticsearch 输出插件
我们可以使用以下命令安装 Elasticsearch 输出插件。
>logstash-plugin install Logstash-output-elasticsearch
日志文件
此配置文件包含一个 Elasticsearch 插件,该插件将输出事件存储在本地安装的 Elasticsearch 中。
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [ "message", "%{LOGLEVEL:loglevel} -
%{NOTSPACE:taskid} - %{NOTSPACE:logger} -
%{WORD:label}( - %{INT:duration:int})?" ]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
mutate {
add_field => {"user" => "tutorialspoint.com"}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}
输入日志
以下代码块显示了输入日志数据。
INFO - 48566 - TRANSACTION_START - start INFO - 48566 - SQL - transaction1 - 320 INFO - 48566 - SQL - transaction1 - 200 INFO - 48566 - TRANSACTION_END - end
在本地主机上启动 Elasticsearch
要在本地主机上启动 Elasticsearch,您应该使用以下命令。
C:\elasticsearch\bin> elasticsearch
Elasticsearch 准备就绪后,您可以通过在浏览器中输入以下 URL 来检查它。
http://本地主机:9200/
回复
以下代码块显示了 Elasticsearch 在 localhost 的响应。
{
"name" : "Doctor Dorcas",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.1.1",
"build_hash" : "40e2c53a6b6c2972b3d13846e450e66f4375bd71",
"build_timestamp" : "2015-12-15T13:05:55Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
注意– 有关 Elasticsearch 的更多信息,您可以单击以下链接。
https://www.tutorialspoint.com/elasticsearch/index.html
现在,使用上述 Logstash.conf 运行 Logstash
>Logstash –f Logstash.conf
在输出日志中粘贴上述文本后,该文本将被 Logstash 存储在 Elasticsearch 中。您可以通过在浏览器中输入以下 URL 来检查存储的数据。
http://localhost:9200/logstash-2017.01.01/_search?pretty
回复
是存放在索引Logstash-2017.01.01中的JSON格式的数据。
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 10,
"max_score" : 1.0,
"hits" : [ {
"_index" : "logstash-2017.01.01",
"_type" : "logs",
"_id" : "AVlZ9vF8hshdrGm02KOs",
"_score" : 1.0,
"_source":{
"duration":200,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2017-01-01T12:17:49.140Z","loglevel":"INFO",
"logger":"SQL","@version":"1","host":"wcnlab-PC",
"label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 200\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
},
{
"_index" : "logstash-2017.01.01",
"_type" : "logs",
"_id" : "AVlZ9vF8hshdrGm02KOt",
"_score" : 1.0,
"_source":{
"sql_duration":520,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2017-01-01T12:17:49.145Z","loglevel":"INFO",
"logger":"TRANSACTION_END","@version":"1","host":"wcnlab-PC",
"label":"end",
"message":" INFO - 48566 - TRANSACTION_END - end\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
}
}
}
Logstash – 支持的输出
Logstash 提供了多个插件来支持各种数据存储或搜索引擎。日志的输出事件可以发送到输出文件、标准输出或 Elasticsearch 等搜索引擎。Logstash 支持三种类型的输出,它们是 –
- 标准输出
- 文件输出
- 空输出
现在让我们详细讨论其中的每一个。
标准输出 (stdout)
它用于将过滤后的日志事件作为数据流生成到命令行界面。这是将数据库事务的总持续时间生成到标准输出的示例。
日志文件
此配置文件包含一个 stdout 输出插件,用于将总 sql_duration 写入标准输出。
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} - %{NOTSPACE:taskid}
- %{NOTSPACE:logger} - %{WORD:label}( - %{INT:duration:int})?"
]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
}
output {
if [logger] == "TRANSACTION_END" {
stdout {
codec => line{format => "%{sql_duration}"}
}
}
}
注意– 如果尚未安装,请安装聚合过滤器。
>logstash-plugin install Logstash-filter-aggregate
运行 Logstash
我们可以使用以下命令运行 Logstash。
>logstash –f logsatsh.conf
输入日志
以下代码块显示了输入日志数据。
INFO - 48566 - TRANSACTION_START - start INFO - 48566 - SQL - transaction1 - 320 INFO - 48566 - SQL - transaction1 - 200 INFO - 48566 - TRANSACTION_END – end
stdout(它将是 Windows 中的命令提示符或 UNIX 中的终端)
这是总的 sql_duration 320 + 200 = 520。
520
文件输出
Logstash 还可以将过滤器日志事件存储到输出文件中。我们将使用上述示例并将输出存储在文件中,而不是 STDOUT。
日志文件
此 Logstash 配置文件指示 Logstash 将总 sql_duration 存储到输出日志文件。
input {
file {
path => "C:/tpwork/logstash/bin/log/input1.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} - %{NOTSPACE:taskid} -
%{NOTSPACE:logger} - %{WORD:label}( - %{INT:duration:int})?"
]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
}
output {
if [logger] == "TRANSACTION_END" {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
codec => line{format => "%{sql_duration}"}
}
}
}
运行日志
我们可以使用以下命令运行 Logstash。
>logstash –f logsatsh.conf
输入日志
以下代码块显示了输入日志数据。
INFO - 48566 - TRANSACTION_START - start INFO - 48566 - SQL - transaction1 - 320 INFO - 48566 - SQL - transaction1 - 200 INFO - 48566 - TRANSACTION_END – end
输出日志
以下代码块显示了输出日志数据。
520
空输出
这是一个特殊的输出插件,用于分析输入和过滤插件的性能。
Logstash – 插件
Logstash 为其管道的所有三个阶段(输入、过滤器和输出)提供了各种插件。这些插件帮助用户从各种来源(如 Web 服务器、数据库、网络协议等)捕获日志。
捕获后,Logstash 可以将数据解析并转换为用户需要的有意义的信息。最后,Logstash 可以将有意义的信息发送或存储到各种目标源,如 Elasticsearch、AWS Cloudwatch 等。
输入插件
Logstash 中的输入插件可帮助用户从各种来源提取和接收日志。使用输入插件的语法如下 –
Input {
Plugin name {
Setting 1……
Setting 2……..
}
}
您可以使用以下命令下载输入插件 –
>Logstash-plugin install Logstash-input-<plugin name>
Logstash-plugin 实用程序位于Logstash 安装目录的bin 文件夹中。下表列出了 Logstash 提供的输入插件。
| Sr.No. | 插件名称和说明 |
|---|---|
| 1 |
beats 从 elastic beats 框架中获取日志数据或事件。 |
| 2 |
cloudwatch 从 CloudWatch 中提取事件,这是 Amazon Web Services 提供的 API。 |
| 3 |
couchdb_changes 来自使用此插件提供的 couchdb 的 _chages URI 的事件。 |
| 4 |
drupal_dblog 使用启用的 DBLog 提取 drupal 的看门狗日志记录数据。 |
| 5 |
Elasticsearch 检索在 Elasticsearch 集群中执行的查询的结果。 |
| 6 |
eventlog 从 Windows 事件日志中获取事件。 |
| 7 |
exec 获取 shell 命令输出作为 Logstash 中的输入。 |
| 8 |
file 从输入文件中获取事件。当 Logstash 与输入源一起在本地安装并且可以访问输入源日志时,这很有用。 |
| 9 |
generator 它用于测试目的,这会创建随机事件。 |
| 10 |
github 从 GitHub webhook 捕获事件。 |
| 11 |
graphite 从石墨监控工具获取指标数据。 |
| 12 |
heartbeat 它还用于测试并产生类似心跳的事件 |
| 13 |
http 通过两种网络协议收集日志事件,即 http 和 https。 |
| 14 |
http_poller 它用于将 HTTP API 输出解码为事件。 |
| 15 |
jdbc 它将 JDBC 事务转换为 Logstash 中的事件。 |
| 16 |
jmx 使用 JMX 从远程 Java 应用程序中提取指标。 |
| 17 |
log4j 通过 TCP 套接字从 Log4j 的 socketAppender 对象捕获事件。 |
| 18 |
rss 将命令行工具的输出作为 Logstash 中的输入事件。 |
| 19 |
tcp 通过 TCP 套接字捕获事件。 |
| 20 |
从 Twitter 流 API 收集事件。 |
| 21 |
unix 通过 UNIX 套接字收集事件。 |
| 22 |
websocket 通过 websocket 协议捕获事件。 |
| 23 |
xmpp 通过 Jabber/xmpp 协议读取事件。 |
插件设置
所有插件都有其特定的设置,这有助于指定插件中的重要字段,如端口、路径等。我们将讨论一些输入插件的设置。
文件
此输入插件用于直接从输入源中存在的日志或文本文件中提取事件。它的工作方式类似于 UNIX 中的 tail 命令,保存上次读取的游标并仅从输入文件中读取新追加的数据,但可以使用 star_position 设置进行更改。以下是此输入插件的设置。
| Setting Name | 默认值 | 描述 |
|---|---|---|
| add_field | {} | 将新字段附加到输入事件。 |
| close_older | 3600 | 上次读取时间(以秒为单位)超过此插件中指定的文件将被关闭。 |
| codec | “清楚的” | 它用于在进入 Logstash 管道之前对数据进行解码。 |
| delimiter | “\n” | 它用于指定新的行分隔符。 |
| discover_interval | 15 | 它是在指定路径中发现新文件之间的时间间隔(以秒为单位)。 |
| enable_metric | 真的 | 它用于启用或禁用指定插件的指标报告和收集。 |
| exclude | 它用于指定应从输入插件中排除的文件名或模式。 | |
| Id | 为该插件实例指定唯一标识。 | |
| max_open_files | 它随时指定 Logstash 的最大输入文件数。 | |
| path | 指定文件的路径,它可以包含文件名的模式。 | |
| start_position | “结尾” | 如果需要,您可以更改为“开始”;最初 Logstash 应该从头开始读取文件,而不仅仅是新的日志事件。 |
| start_interval | 1 | 它以秒为单位指定时间间隔,在此之后 Logstash 检查已修改的文件。 |
| tags | 要添加任何其他信息,例如 Logstash,当任何日志事件未能符合指定的 grok 过滤器时,它会在标签中添加“_grokparsefailure”。 | |
| type | 这是一个特殊字段,您可以将其添加到输入事件中,它在过滤器和 kibana 中很有用。 |
弹性搜索
这个特定的插件用于读取 Elasticsearch 集群中的搜索查询结果。以下是此插件中使用的设置 –
| Setting Name | 默认值 | 描述 |
|---|---|---|
| add_field | {} | 与文件插件相同,用于在输入事件中附加字段。 |
| ca_file | 用于指定 SSL 证书颁发机构文件的路径。 | |
| codec | “清楚的” | 它用于在进入 Logstash 管道之前解码来自 Elasticsearch 的输入事件。 |
| docinfo | “错误的” | 如果您想从 Elasticsearch 引擎中提取索引、类型和 id 等附加信息,您可以将其更改为 true。 |
| docinfo_fields | [“_index”, “_type”, “_id”] | 您可以在 Logstash 输入中删除不需要的任何字段。 |
| enable_metric | 真的 | 它用于启用或禁用该插件实例的报告和指标收集。 |
| hosts | 它用于指定所有弹性搜索引擎的地址,这些引擎将作为该 Logstash 实例的输入源。语法是host:port 或IP:port。 | |
| Id | 它用于为该特定输入插件实例提供唯一标识号。 | |
| index | “logstash-*” | 它用于指定索引名称或模式,Logstash 将监视 Logstash 以进行输入。 |
| password | 用于身份验证。 | |
| query | “{ \”sort\”: [ \”_doc\” ] }” | 查询执行。 |
| ssl | 错误的 | 启用或禁用安全套接字层。 |
| tags | 在输入事件中添加任何附加信息。 | |
| type | 它用于对输入表单进行分类,以便在后期轻松搜索所有输入事件。 | |
| user | 出于真实目的。 |
事件簿
这个输入插件从 windows 服务器的 win32 API 读取数据。以下是此插件的设置 –
| Setting Name | 默认值 | 描述 |
|---|---|---|
| add_field | {} | 与文件插件相同,用于在输入事件中附加一个字段 |
| codec | “清楚的” | 用于解码来自windows的输入事件;在进入 Logstash 管道之前 |
| logfile | [“应用”、“安全”、“系统”] | 输入日志文件中所需的事件 |
| interval | 1000 | 它以毫秒为单位,定义了两次连续检查新事件日志之间的间隔 |
| tags | 在输入事件中添加任何附加信息 | |
| type | 它用于将特定插件的输入表单分类为给定类型,以便在后期轻松搜索所有输入事件 |
推特
此输入插件用于从其 Streaming API 收集 twitter 的提要。下表描述了此插件的设置。
| Setting Name | 默认值 | 描述 |
|---|---|---|
| add_field | {} | 与文件插件相同,用于在输入事件中附加一个字段 |
| codec | “清楚的” | 用于解码来自windows的输入事件;在进入 Logstash 管道之前 |
| consumer_key | 它包含 Twitter 应用程序的使用者密钥。欲了解更多信息,请访问https://dev.twitter.com/apps/new | |
| consumer_secret | 它包含 Twitter 应用程序的消费者密钥。欲了解更多信息,请访问https://dev.twitter.com/apps/new | |
| enable_metric | 真的 | 它用于启用或禁用该插件实例的报告和指标收集 |
| follows |
它指定用逗号分隔的用户 ID,LogStash 会检查这些用户在 Twitter 中的状态。 欲了解更多信息,请访问 |
|
| full_tweet | 错误的 | 如果您希望 Logstash 读取从 twitter API 返回的完整对象,您可以将其更改为 true |
| id | 它用于为该特定输入插件实例提供唯一标识号 | |
| ignore_retweets | 错误的 | 您可以更改设置为 true 以忽略输入推特提要中的转推 |
| keywords | 这是一组关键字,需要在 twitters 输入源中进行跟踪 | |
| language | 它定义了 LogStash 需要的来自输入 twitter 提要的推文的语言。这是一个标识符数组,它定义了 Twitter 中的特定语言 | |
| locations | 根据指定的位置从输入源中过滤掉推文。这是一个数组,其中包含位置的经度和纬度 | |
| oauth_token | 这是一个必需的文件,其中包含用户 oauth 令牌。欲了解更多信息,请访问以下链接https://dev.twitter.com/apps | |
| oauth_token_secret | 这是一个必需的文件,其中包含用户 oauth 秘密令牌。欲了解更多信息,请访问以下链接https://dev.twitter.com/apps | |
| tags | 在输入事件中添加任何附加信息 | |
| type | 它用于将特定插件的输入表单分类为给定类型,以便在后期轻松搜索所有输入事件 |
TCP
TCP 用于通过 TCP 套接字获取事件;它可以从模式设置中指定的用户连接或服务器读取。下表描述了此插件的设置 –
| Setting Name | 默认值 | 描述 |
|---|---|---|
| add_field | {} | 与文件插件相同,用于在输入事件中附加一个字段 |
| codec | “清楚的” | 用于解码来自windows的输入事件;在进入 Logstash 管道之前 |
| enable_metric | 真的 | 它用于启用或禁用该插件实例的报告和指标收集 |
| host | “0.0.0.0” | 客户端依赖的服务器操作系统的地址 |
| id | 它包含 Twitter 应用程序的消费者密钥 | |
| mode | “服务器” | 它用于指定输入源是服务器还是客户端。 |
| port | 它定义了端口号 | |
| ssl_cert | 用于指定SSL证书的路径 | |
| ssl_enable | 错误的 | 启用或禁用 SSL |
| ssl_key | 指定 SSL 密钥文件的路径 | |
| tags | 在输入事件中添加任何附加信息 | |
| type | 它用于将特定插件的输入表单分类为给定类型,以便在后期轻松搜索所有输入事件 |
Logstash – 输出插件
Logstash 支持各种输出源和不同的技术,如数据库、文件、电子邮件、标准输出等。
使用输出插件的语法如下 –
output {
Plugin name {
Setting 1……
Setting 2……..
}
}
您可以使用以下命令下载输出插件 –
>logstash-plugin install logstash-output-<plugin name>
该Logstash-插件工具存在于Logstash安装目录下的bin文件夹。下表描述了 Logstash 提供的输出插件。
| Sr.No. | 插件名称和说明 |
|---|---|
| 1 |
CloudWatch 此插件用于将聚合指标数据发送到亚马逊 Web 服务的 CloudWatch。 |
| 2 |
csv 它用于以逗号分隔的方式编写输出事件。 |
| 3 |
Elasticsearch 用于将输出日志存储在 Elasticsearch 索引中。 |
| 4 |
它用于在生成输出时发送通知电子邮件。用户可以在电子邮件中添加有关输出的信息。 |
| 5 |
exec 它用于运行与输出事件匹配的命令。 |
| 6 |
ganglia 它将指标扭曲到 Gangila 的 gmond。 |
| 7 |
gelf 它用于以 GELF 格式为 Graylog2 生成输出。 |
| 8 |
google_bigquery 它将事件输出到 Google BigQuery。 |
| 9 |
google_cloud_storage 它将输出事件存储到 Google Cloud Storage。 |
| 10 |
graphite 它用于将输出事件存储到 Graphite。 |
| 11 |
graphtastic 它用于在 Windows 上编写输出指标。 |
| 12 |
hipchat 它用于将输出日志事件存储到 HipChat。 |
| 13 |
http 它用于将输出日志事件发送到 http 或 https 端点。 |
| 14 |
influxdb 它用于在 InfluxDB 中存储输出事件。 |
| 15 |
irc 它用于将输出事件写入 irc。 |
| 16 |
mongodb 它将输出数据存储在 MongoDB 中。 |
| 17 |
nagios 它用于将被动检查结果通知 Nagios。 |
| 18 |
nagios_nsca 它用于通过 NSCA 协议将被动检查结果通知 Nagios。 |
| 19 |
opentsdb 它将 Logstash 输出事件存储到 OpenTSDB。 |
| 20 |
pipe 它将输出事件流式传输到另一个程序的标准输入。 |
| 21 |
rackspace 用于将输出的日志事件发送到 Rackspace Cloud 的 Queue 服务。 |
| 22 |
redis 它使用 rpush 命令将输出的日志数据发送到 Redis 队列。 |
| 23 |
riak 它用于将输出事件存储到 Riak 分布式键/值对。 |
| 24 |
s3 它将输出日志数据存储到 Amazon Simple Storage Service。 |
| 25 |
sns 它用于将输出事件发送到 Amazon 的 Simple Notification Service。 |
| 26 |
solr_http 它在 Solr 中索引和存储输出日志数据。 |
| 27 |
sps 它用于将事件发送到 AWS 的 Simple Queue Service。 |
| 28 |
statsd 它用于将指标数据发送到 statsd 网络守护程序。 |
| 29 |
stdout 它用于在 CLI 的标准输出(如命令提示符)上显示输出事件。 |
| 30 |
syslog 它用于将输出事件发送到系统日志服务器。 |
| 31 |
tcp 它用于将输出事件发送到 TCP 套接字。 |
| 32 |
udp 它用于通过 UDP 推送输出事件。 |
| 33 |
websocket 它用于通过 WebSocket 协议推送输出事件。 |
| 34 |
xmpp 它用于通过 XMPP 协议推送输出事件。 |
所有插件都有其特定的设置,这有助于指定插件中的重要字段,如端口、路径等。我们将讨论一些输出插件的设置。
弹性搜索
Elasticsearch 输出插件使 Logstash 能够将输出存储在 Elasticsearch 引擎的特定集群中。这是用户的著名选择之一,因为它包含在 ELK Stack 包中,因此为 Devops 提供端到端解决方案。下表描述了此输出插件的设置。
| Setting Name | 默认值 | 描述 |
|---|---|---|
| action | 指数 | 它用于定义在 Elasticsearch 引擎中执行的操作。此设置的其他值是删除、创建、更新等。 |
| cacert | 它包含带有 .cer 或 .pem 的文件路径,用于服务器的证书验证。 | |
| codec | “清楚的” | 它用于在将输出日志数据发送到目标源之前对其进行编码。 |
| doc_as_upset | 错误的 | 此设置用于更新操作的情况。如果在输出插件中未指定文档 ID,它将在 Elasticsearch 引擎中创建一个文档。 |
| document_type | 它用于将相同类型的事件存储在相同的文档类型中。如果未指定,则事件类型用于相同。 | |
| flush_size | 500 | 这用于提高 Elasticsearch 中批量上传的性能 |
| hosts | [“127.0.0.1”] | 它是用于输出日志数据的目标地址数组 |
| idle_flush_time | 1 | 它定义了两次刷新之间的时间限制(秒),Logstash 在此设置中指定的时间限制后强制刷新 |
| index | “logstash-%{+YYYY.MM.dd}” | 用于指定Elasticsearch引擎的索引 |
| manage_temlpate | 真的 | 用于在 Elasticsearch 中应用默认模板 |
| parent | 零 | 用于指定Elasticsearch中父文档的id |
| password | 用于验证对 Elasticsearch 中安全集群的请求 | |
| path | 用于指定 Elasticsearch 的 HTTP 路径。 | |
| pipeline | 零 | 它用于设置摄取管道,用户希望为事件执行 |
| proxy | 用于指定 HTTP 代理 | |
| retry_initial_interval | 2 | 它用于设置批量重试之间的初始时间间隔(秒)。每次重试后都会加倍,直到达到 retry_max_interval |
| retry_max_interval | 64 | 用于设置 retry_initial_interval 的最大时间间隔 |
| retry_on_conflict | 1 | Elasticsearch 更新文档的重试次数 |
| ssl | 启用或禁用保护到 Elasticsearch 的 SSL/TLS | |
| template | 包含自定义模板在 Elasticsearch 中的路径 | |
| template_name | “日志存储” | 这用于在 Elasticsearch 中命名模板 |
| timeout | 60 | 它是对 Elasticsearch 的网络请求的超时时间 |
| upsert | “” | 它更新文档,或者如果 document_id 不存在,它会在 Elasticsearch 中创建一个新文档 |
| user | 它包含在安全的 Elasticsearch 集群中对 Logstash 请求进行身份验证的用户 |
电子邮件
当 Logstash 生成输出时,电子邮件输出插件用于通知用户。下表描述了此插件的设置。
| Setting Name | 默认值 | 描述 |
|---|---|---|
| address | “本地主机” | 这是邮件服务器的地址 |
| attachments | [] | 它包含附加文件的名称和位置 |
| body | “” | 它包含电子邮件的正文,应该是纯文本 |
| cc | 它包含以逗号分隔的电子邮件地址,用于电子邮件抄送 | |
| codec | “清楚的” | 它用于在将输出日志数据发送到目标源之前对其进行编码。 |
| contenttype | “文本/html;字符集= UTF-8” | 它用于电子邮件的内容类型 |
| debug | 错误的 | 用于在调试模式下执行邮件中继 |
| domain | “本地主机” | 它用于设置发送电子邮件的域 |
| from | “[email protected]” | 它用于指定发件人的电子邮件地址 |
| htmlbody | “” | 用于指定 html 格式的邮件正文 |
| password | 它用于与邮件服务器进行身份验证 | |
| port | 25 | 用于定义与邮件服务器通信的端口 |
| replyto | 用于指定email回复字段的email id | |
| subject | “” | 它包含电子邮件的主题行 |
| use_tls | 错误的 | 启用或禁用与邮件服务器通信的 TSL |
| username | 包含用于与服务器进行身份验证的用户名 | |
| via | “smtp” | 它定义了 Logstash 发送电子邮件的方法 |
网址
此设置用于通过 http 将输出事件发送到目的地。这个插件有以下设置 –
| Setting Name | 默认值 | 描述 |
|---|---|---|
| automatic_retries | 1 | 用于设置logstash的http请求重试次数 |
| cacert | 它包含服务器证书验证的文件路径 | |
| codec | “清楚的” | 它用于在将输出日志数据发送到目标源之前对其进行编码。 |
| content_type | I 指定对目的服务器的http请求的内容类型 | |
| cookies | 真的 | 它用于启用或禁用 cookie |
| format | “json” | 用于设置http请求体的格式 |
| headers | 它包含http头的信息 | |
| http_method | “” | 用于指定logstash在请求中使用的http方法,取值可以是“put”、“post”、“patch”、“delete”、“get”、“head” |
| request_timeout | 60 | 它用于与邮件服务器进行身份验证 |
| url | 指定 http 或 https 端点是此插件的必需设置 |
标准输出
stdout 输出插件用于在命令行界面的标准输出上写入输出事件。它是 Windows 中的命令提示符和 UNIX 中的终端。此插件具有以下设置 –
| Setting Name | 默认值 | 描述 |
|---|---|---|
| codec | “清楚的” | 它用于在将输出日志数据发送到目标源之前对其进行编码。 |
| workers | 1 | 它用于指定输出的工人数量 |
统计数据
它是一个网络守护进程,用于通过 UDP 将矩阵数据发送到目标后端服务。它是 Windows 中的命令提示符和 UNIX 中的终端。这个插件有以下设置 –
| Setting Name | 默认值 | 描述 |
|---|---|---|
| codec | “清楚的” | 它用于在将输出日志数据发送到目标源之前对其进行编码。 |
| count | {} | 它用于定义要在指标中使用的计数 |
| decrement | [] | 它用于指定递减指标名称 |
| host | “本地主机” | 它包含 statsd 服务器的地址 |
| increment | [] | 它用于指定增量度量名称 |
| port | 8125 | 它包含statsd服务器的端口 |
| sample_rate | 1 | 它用于指定指标的采样率 |
| sender | “%{主持人}” | 它指定发件人的姓名 |
| set | {} | 它用于指定一个集合度量 |
| timing | {} | 它用于指定时间度量 |
| workers | 1 | 它用于指定输出的工人数量 |
过滤插件
Logstash 支持各种过滤器插件来解析输入日志并将其转换为更结构化且易于查询的格式。
使用过滤器插件的语法如下 –
filter {
Plugin name {
Setting 1……
Setting 2……..
}
}
您可以使用以下命令下载过滤器插件 –
>logstash-plugin install logstash-filter-<plugin name>
Logstash-plugin 实用程序位于 Logstash 安装目录的 bin 文件夹中。下表描述了 Logstash 提供的输出插件。
| Sr.No. | 插件名称和说明 |
|---|---|
| 1 |
aggregate 该插件从相同类型的各种事件中收集或聚合数据,并在最终事件中处理它们 |
| 2 |
alter 它允许用户更改日志事件的字段,而 mutate 过滤器不处理 |
| 3 |
anonymize 它用于用一致的哈希替换字段的值 |
| 4 |
cipher 它用于在将输出事件存储到目标源之前对其进行加密 |
| 5 |
clone 它用于在 Logstash 中创建输出事件的副本 |
| 6 |
collate 它按时间或计数合并来自不同日志的事件 |
| 7 |
csv 该插件根据分隔符解析输入日志中的数据 |
| 8 |
date 它解析事件中字段的日期并将其设置为事件的时间戳 |
| 9 |
dissect 该插件可帮助用户从非结构化数据中提取字段,并使 grok 过滤器可以轻松正确地解析它们 |
| 10 |
drop 它用于删除所有相同类型或任何其他相似的事件 |
| 11 |
elapsed 它用于计算开始和结束事件之间的时间 |
| 12 |
Elasticsearch 它用于将 Elasticsearch 中存在的先前日志事件的字段复制到 Logstash 中的当前字段 |
| 13 |
extractnumbers 它用于从日志事件中的字符串中提取数字 |
| 14 |
geoip 它在事件中添加了一个字段,其中包含日志事件中存在的 IP 位置的纬度和经度 |
| 15 |
grok 是常用的过滤器插件,用于解析事件获取字段 |
| 16 |
i18n 它从日志事件中的文件中删除特殊字符 |
| 17 |
json 它用于在事件中或在事件的特定字段中创建结构化的 Json 对象 |
| 18 |
kv 这个插件在匹配日志数据中的键值对时很有用 |
| 19 |
metrics 它用于聚合指标,例如计算每个事件的持续时间 |
| 20 |
multiline 它也是常用的过滤器插件之一,它可以帮助用户将多行日志数据转换为单个事件。 |
| 21 |
mutate 此插件用于重命名、删除、替换和修改事件中的字段 |
| 22 |
range 它用于根据预期范围和范围内的字符串长度检查事件中字段的数值。 |
| 23 |
ruby 它用于运行任意 Ruby 代码 |
| 24 |
sleep 这使 Logstash 休眠指定的时间 |
| 25 |
split 它用于拆分事件的字段并将所有拆分值放置在该事件的克隆中 |
| 26 |
xml 它用于通过解析日志中存在的 XML 数据来创建事件 |
编解码器插件
编解码器插件可以是输入或输出插件的一部分。这些插件用于更改或格式化日志数据表示。Logstash 提供多个编解码器插件,如下所示 –
| Sr.No. | 插件名称和说明 |
|---|---|
| 1 |
avro 此插件将 Logstash 事件序列化为 avro 数据或将 avro 记录解码为 Logstash 事件 |
| 2 |
cloudfront 此插件从 AWS cloudfront 读取编码数据 |
| 3 |
cloudtrail 该插件用于从 AWS cloudtrail 读取数据 |
| 4 |
collectd 这从称为通过 UDP 收集的二进制协议读取数据 |
| 5 |
compress_spooler 它用于将 Logstash 中的日志事件压缩为假脱机批次 |
| 6 |
dots 这是通过为每个事件设置一个点到标准输出来使用性能跟踪 |
| 7 |
es_bulk 这用于将来自 Elasticsearch 的批量数据转换为 Logstash 事件,包括 Elasticsearch 元数据 |
| 8 |
graphite 此编解码器将石墨中的数据读入事件并将事件转换为石墨格式的记录 |
| 9 |
gzip_lines 该插件用于处理 gzip 编码的数据 |
| 10 |
json 这用于将 Json 数组中的单个元素转换为单个 Logstash 事件 |
| 11 |
json_lines 它用于处理带有换行符的 Json 数据 |
| 12 |
line 它插件将在单个 live 中读取和写入事件,这意味着在换行分隔符之后会有一个新事件 |
| 13 |
multiline 它用于将多行日志数据转换为单个事件 |
| 14 |
netflow 此插件用于将 nertflow v5/v9 数据转换为 logstash 事件 |
| 15 |
nmap 它将 nmap 结果数据解析为 XML 格式 |
| 16 |
plain 这读取没有分隔符的文本 |
| 17 |
rubydebug 这个插件将使用 Ruby Awesome 打印库编写输出 Logstash 事件 |
构建你自己的插件
您还可以在 Logstash 中创建自己的插件,以满足您的需求。Logstash-plugin 实用程序用于创建自定义插件。在这里,我们将创建一个过滤器插件,它将在事件中添加自定义消息。
生成基础结构
用户可以使用 logstash-plugin 实用程序的 generate 选项生成必要的文件,也可以在 GitHub 上找到它。
>logstash-plugin generate --type filter --name myfilter --path c:/tpwork/logstash/lib
在这里,type选项用于指定插件是输入、输出或过滤器。在这个例子中,我们正在创建一个名为myfilter的过滤器插件。path 选项用于指定路径,您希望在其中创建插件目录。执行上述命令后,您将看到创建了一个目录结构。
开发插件
您可以在插件目录的\lib\logstash\filters文件夹中找到插件的代码文件。文件扩展名为.rb。
在我们的例子中,代码文件位于以下路径中 –
C:\tpwork\logstash\lib\logstash-filter-myfilter\lib\logstash\filters\myfilter.rb
我们将消息更改为 − 默认⇒“嗨,您正在tutorialspoint.com 上学习”并保存文件。
安装插件
安装这个插件需要修改Logstash的Gemfile。你可以在Logstash的安装目录中找到这个文件。在我们的例子中,它将在C:\tpwork\logstash 中。使用任何文本编辑器编辑此文件并在其中添加以下文本。
gem "logstash-filter-myfilter",:path => "C:/tpwork/logstash/lib/logstash-filter-myfilter"
在上面的命令中,我们指定了插件的名称以及我们可以在哪里找到它进行安装。然后,运行 Logstash-plugin 实用程序来安装此插件。
>logstash-plugin install --no-verify
测试
在这里,我们在前面的示例之一中添加了myfilter –
日志文件
此 Logstash 配置文件在 grok 过滤器插件之后的过滤器部分中包含 myfilter。
input {
file {
path => "C:/tpwork/logstash/bin/log/input1.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} - %{NOTSPACE:taskid} -
%{NOTSPACE:logger} - %{WORD:label}( - %{INT:duration:int})?" ]
}
myfilter{}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output1.log"
codec => rubydebug
}
}
运行日志
我们可以使用以下命令运行 Logstash。
>logstash –f logsatsh.conf
输入日志
以下代码块显示了输入日志数据。
INFO - 48566 - TRANSACTION_START - start
输出日志
以下代码块显示了输出日志数据。
{
"path" => "C:/tpwork/logstash/bin/log/input.log",
"@timestamp" => 2017-01-07T06:25:25.484Z,
"loglevel" => "INFO",
"logger" => "TRANSACTION_END",
"@version" => "1",
"host" => "Dell-PC",
"label" => "end",
"message" => "Hi, You are learning this on tutorialspoint.com",
"taskid" => "48566",
"tags" => []
}
在 Logstash 上发布
开发人员还可以通过将其上传到 github 并遵循 Elasticsearch 公司定义的标准化步骤将他/她的自定义插件发布到 Logstash。
有关发布的更多信息,请参阅以下 URL –
https://www.elastic.co/guide/en/logstash/current/contributing-to-logstash.html
Logstash – 监控 API
Logstash 提供 API 来监控其性能。这些监控 API 提取有关 Logstash 的运行时指标。
节点信息 API
该API用于获取Logstash的节点信息。它以 JSON 格式返回 OS、Logstash 管道和 JVM 的信息。
您可以通过使用以下 URL 向 Logstash发送获取请求来提取信息–
GET http://localhost:9600/_node?pretty
回复
以下是节点信息 API 的响应。
{
"host" : "Dell-PC",
"version" : "5.0.1",
"http_address" : "127.0.0.1:9600",
"pipeline" : {
"workers" : 4,
"batch_size" : 125,
"batch_delay" : 5,
"config_reload_automatic" : false,
"config_reload_interval" : 3
},
"os" : {
"name" : "Windows 7",
"arch" : "x86",
"version" : "6.1",
"available_processors" : 4
},
"jvm" : {
"pid" : 312,
"version" : "1.8.0_111",
"vm_name" : "Java HotSpot(TM) Client VM",
"vm_version" : "1.8.0_111",
"vm_vendor" : "Oracle Corporation",
"start_time_in_millis" : 1483770315412,
"mem" : {
"heap_init_in_bytes" : 16777216,
"heap_max_in_bytes" : 1046937600,
"non_heap_init_in_bytes" : 163840,
"non_heap_max_in_bytes" : 0
},
"gc_collectors" : [ "ParNew", "ConcurrentMarkSweep" ]
}
}
您还可以通过在 URL 中添加它们的名称来获取 Pipeline、OS 和 JVM 的特定信息。
GET http://localhost:9600/_node/os?pretty GET http://localhost:9600/_node/pipeline?pretty GET http://localhost:9600/_node/jvm?pretty
插件信息 API
该 API 用于获取有关 Logstash 中已安装插件的信息。您可以通过向下面提到的 URL 发送获取请求来检索此信息 –
GET http://localhost:9600/_node/plugins?pretty
回复
以下是插件信息 API 的响应。
{
"host" : "Dell-PC",
"version" : "5.0.1",
"http_address" : "127.0.0.1:9600",
"total" : 95,
"plugins" : [ {
"name" : "logstash-codec-collectd",
"version" : "3.0.2"
},
{
"name" : "logstash-codec-dots",
"version" : "3.0.2"
},
{
"name" : "logstash-codec-edn",
"version" : "3.0.2"
},
{
"name" : "logstash-codec-edn_lines",
"version" : "3.0.2"
},
............
}
节点统计 API
该 API 用于提取 JSON 对象中的 Logstash(Memory、Process、JVM、Pipeline)的统计信息。您可以通过向下面提到的 URLS 发送获取请求来检索此信息 –
GET http://localhost:9600/_node/stats/?pretty GET http://localhost:9600/_node/stats/process?pretty GET http://localhost:9600/_node/stats/jvm?pretty GET http://localhost:9600/_node/stats/pipeline?pretty
热线程 API
此 API 检索有关 Logstash 中的热线程的信息。热线程是 Java 线程,它具有较高的 CPU 使用率并且运行时间比正常执行时间长。您可以通过向下面提到的 URL 发送获取请求来检索此信息 –
GET http://localhost:9600/_node/hot_threads?pretty
用户可以使用以下 URL 以更具可读性的形式获取响应。
GET http://localhost:9600/_node/hot_threads?human = true
Logstash – 安全和监控
在本章中,我们将讨论 Logstash 的安全和监控方面。
监控
Logstash 是一个非常好的监控生产环境中的服务器和服务的工具。生产环境中的应用程序会产生不同类型的日志数据,如访问日志、错误日志等。Logstash 可以使用过滤器插件对错误、访问或其他事件的数量进行计数或分析。这种分析和计数可用于监控不同的服务器及其服务。
Logstash 提供了HTTP Poller 等插件来监控网站状态监控。在这里,我们正在监控一个名为mysite的网站,该网站托管在本地 Apache Tomcat 服务器上。
日志文件
在这个配置文件中,http_poller 插件用于在间隔设置中指定的时间间隔后点击插件中指定的站点。最后,它将站点的状态写入标准输出。
input {
http_poller {
urls => {
site => "http://localhost:8080/mysite"
}
request_timeout => 20
interval => 30
metadata_target => "http_poller_metadata"
}
}
output {
if [http_poller_metadata][code] == 200 {
stdout {
codec => line{format => "%{http_poller_metadata[response_message]}"}
}
}
if [http_poller_metadata][code] != 200 {
stdout {
codec => line{format => "down"}
}
}
}
运行日志
我们可以使用以下命令运行 Logstash。
>logstash –f logstash.conf
标准输出
如果站点已启动,则输出将是 –
Ok
如果我们使用Tomcat的Manager App停止站点,输出将更改为 –
down
安全
Logstash 提供了大量用于与外部系统进行安全通信的功能,并支持身份验证机制。所有 Logstash 插件都支持通过 HTTP 连接进行身份验证和加密。
HTTP 协议的安全性
Logstash 提供的各种插件(如 Elasticsearch 插件)中都有用于身份验证的用户和密码等设置。
elasticsearch {
user => <username>
password => <password>
}
另一种身份验证是Elasticsearch 的PKI(公钥基础设施)。开发者需要在 Elasticsearch 输出插件中定义两个设置来启用 PKI 身份验证。
elasticsearch {
keystore => <string_value>
keystore_password => <password>
}
在 HTTPS 协议中,开发者可以使用权威机构的证书进行 SSL/TLS。
elasticsearch {
ssl => true
cacert => <path to .pem file>
}
传输协议的安全性
要在 Elasticsearch 中使用传输协议,用户需要将协议设置设置为传输。这避免了 JSON 对象的解组并提高了效率。
基本身份验证与 Elasticsearch 输出协议中的 http 协议中执行的相同。
elasticsearch {
protocol => “transport”
user => <username>
password => <password>
}
PKI 身份验证还需要 SSL 设置与 Elasticsearch 输出协议中的其他设置为真 –
elasticsearch {
protocol => “transport”
ssl => true
keystore => <string_value>
keystore_password => <password>
}
最后,SSL 安全需要比其他通信安全方法更多的设置。
elasticsearch {
ssl => true
ssl => true
keystore => <string_value>
keystore_password => <password>
truststore =>
truststore_password => <password>
}
Logstash 的其他安全优势
Logstash 可以帮助输入系统源以防止拒绝服务攻击等攻击。监控日志并分析这些日志中的不同事件可以帮助系统管理员检查传入连接和错误的变化。这些分析有助于查看攻击是否正在或将要发生在服务器上。
Elasticsearch 公司的其他产品,例如x-pack和filebeat,提供了一些与 Logstash 安全通信的功能。
