情节 – 直方图
情节 – 直方图
由 Karl Pearson 引入,直方图是数值数据分布的准确表示,它是对连续变量 (CORAL) 概率分布的估计。它看起来类似于条形图,但是,条形图涉及两个变量,而直方图只涉及一个变量。
直方图需要bin(或bucket)将整个值范围划分为一系列区间——然后计算每个区间有多少值。bin 通常指定为变量的连续、非重叠区间。垃圾箱必须相邻,并且通常大小相同。在箱子上方竖立一个矩形,其高度与频率(每个箱子中的病例数)成正比。
直方图跟踪对象由go.Histogram()函数返回。它的定制是通过各种参数或属性完成的。一个基本参数是 x 或 y 设置为列表、numpy 数组或Pandas 数据帧对象,这些对象将分布在 bin 中。
默认情况下,Plotly 将数据点分布在自动调整大小的 bin 中。但是,您可以定义自定义 bin 大小。为此,您需要将 autobins 设置为 false,指定nbins(bin 数量)、其开始和结束值以及大小。
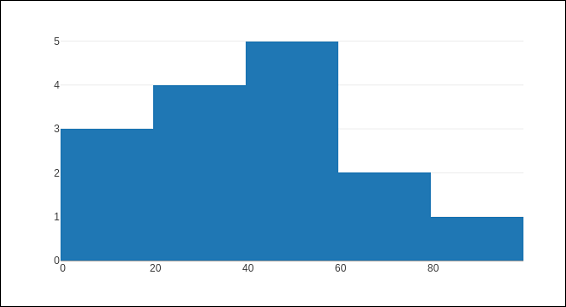
以下代码生成一个简单的直方图,显示学生在班级内的分数分布(自动调整大小) –
import numpy as np x1 = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27]) data = [go.Histogram(x = x1)] fig = go.Figure(data) iplot(fig)
输出如下所示 –
所述go.Histogram()函数接受histnorm,其指定用于该直方图跟踪正常化的类型。默认为“”,每个条形的跨度对应于出现的次数(即位于 bin 内的数据点数)。如果分配了“percent” / “probability”,则每个条形的跨度对应于相对于样本点总数的百分比/发生率。如果它等于“密度”,则每个条形的跨度对应于 bin 中出现的次数除以 bin 间隔的大小。
还有一个histfunc参数,其默认值为count。因此,bin 上矩形的高度对应于数据点的计数。它可以设置为 sum、avg、min 或 max。
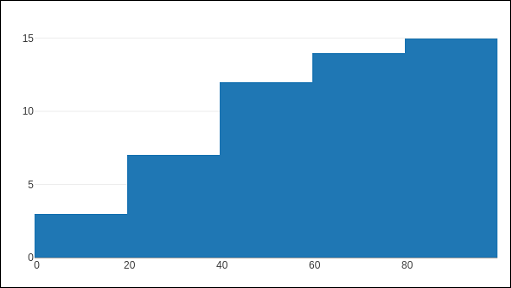
的直方图()函数可以被设置为显示在连续的二进制位值的累积分布。为此,您需要将累积属性设置为启用。结果如下所示 –
data=[go.Histogram(x = x1, cumulative_enabled = True)] fig = go.Figure(data) iplot(fig)
输出如下所述 –